“I love and am used to keeping a distance with those changed things. Only in this way can I know what will not be abandoned by time.”
2. Java高级特性设计
2.1 Java集合框架
Java集合框架下有很类,给出其集合框架图如下所示。(其中,黄色的代表接口,绿色的是抽象类,蓝色的是具体类)。


TreeSet类与散列集(HashSet)十分类似,不过它比散列集有所改进。树集是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值自动地按照排序后的顺序呈现。排序是用树结构完成的(目前所实现使用的是红黑树)。(注意:对于要使用树集,必须能够比较元素。即这些元素必须实现Comparable接口,或者构造集时必须提供一个Comparator。)
Eg: 具体内容参考Java核心技术书籍。
2.2 并发
2.2.1 什么是伪共享
伪共享:当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。(具体内容看上面的文章),给出一个例子,其充分说明了伪共享是怎么回事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class FalseSharingTest {
public static void main(String[] args)throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer)throws InterruptedException{
long start = System.currentTimeMillis();
Thread thread1 = new Thread(() ->{
for (int i = 0; i < 100000000; i++){
pointer.x++;
}
});
Thread thread2 = new Thread(() ->{
for (int i = 0; i < 100000000; i++){
pointer.y++;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}
}
class Pointer{
volatile long x;
volatile long y;
}
这个例子中,我们声明了一个 Pointer 的类,它包含 x 和 y 两个变量(必须声明为volatile,保证可见性),一个线程对 x 进行自增1亿次,一个线程对 y 进行自增1亿次。
可以看到,x 和 y 完全没有任何关系,但是更新 x 的时候会把其它包含 x 的缓存行失效,同时也就失效了 y,运行这段程序输出的时间为 3890ms。
避免伪共享的方法:例如一个缓存行是64个字节,一个long类型是8个字节,所以避免伪共享也很简单,其大概有以下三种方法:
1.在两个long类型的变量之间再加7个long类型
例如把上面的Pointer改成下面的这个结构:
1
2
3
4
5
class Pointer{
volatile long x;
long p1, p2,p3,p4,p5,p6,p7;
volatile long y;
}
再次运行程序,会发现输出时间神奇的缩短为了 695ms。
2.重新创建自己的 long 类型,而不是 java 自带的 long
修改Pointer如下所示:
1
2
3
4
5
6
7
8
9
class MyLong{
volatile long value;
long p1, p2,p3,p4,p5,p6,p7;
}
class Pointer{
MyLong x = new MyLong();
MyLong y = new MyLong();
}
同时把 pointer.x++; 修改为 pointer.x.value++;,把 pointer.y++; 修改为 pointer.y.value++;,再次运行程序发现时间是 724ms。
3.使用 @sun.misc.Contended 注解(java8)
修改MyLong如下:
1
2
3
4
@sun.misc.Contended
class MyLong{
volatile long value;
}
默认使用这个注解是无效的,需要在JVM启动参数加上 -XX:-RestrictContended才会生效,,再次运行程序发现时间是 718ms。
注意,以上三种方式中的前两种是通过加字段的形式实现的,加的字段又没有地方使用,可能会被jvm优化掉,所以建议使用第三种方式。
2.3 Java SE8的流库
流和集合之间的区别:
- 流并不存储其数据。这些元素可能存储在底层的集合中,或者是按需生成的。
- 流的操作不会修改其数据源。例如,filter方法不会从新的流中移除元素,而是会生成一个新的流,其中不包括被过滤掉的元素。
- 流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
1.2 Map接口
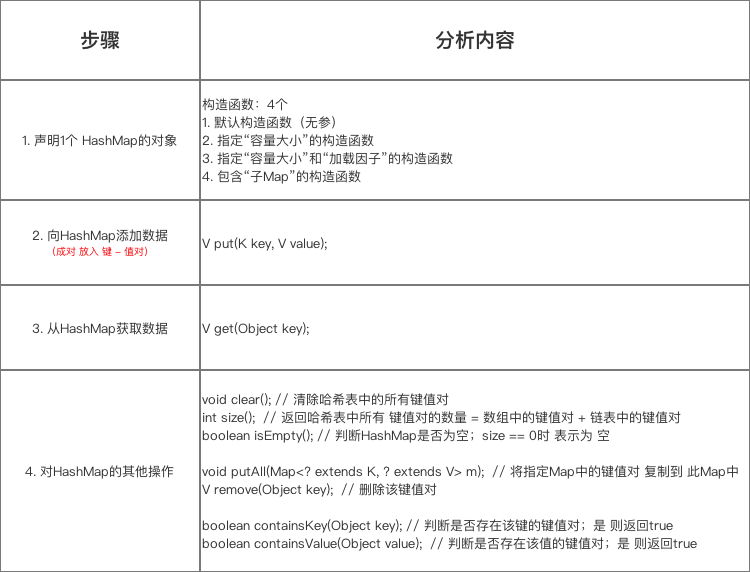
Map用于保存具有映射关系的数据,它是由一系列键值对组成的集合,提供了key到value的映射,在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。Map接口中定义了如下常见的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
void clear(); //删除Map对象中的所有key-value键值对
boolean containsKey(Object key); //查询Map中是否包含指定的key,如果包含则返回true
boolean containsValue(Object value); //查询Map中是否包含一个或多个value,如果包含则返回true
Set<Map.Entry<K, V>> entrySet(); //返回Map中包含的key-value所组成的Set集合,每个集合元素都是Map.Entry(Entry是Map的内部类)对象
V get(Object key); //返回指定key所对应的value;如果此Map中不包含该key,则返回null
boolean isEmpty(); //查询该Map是否为空
Set<K> keySet(); // 返回该Map中所有key组成的Set集合
V put(K key, V value); //添加一个key-value对,如果当前Map中已经存在一个与该key相等的key-value对,则新的key-value对会覆盖原来的key-value。
void putAll(Map<? extends K, ? extends V> m); //将指定Map中的key-value对复制到该map中
V remove(Object key); //删除指定key锁对应的key-value对,返回被删除key所关联的value,如果该key不存在,则返回null
default boolean remove(Object key, Object value){...}; //删除指定key,value所对应的key-value对
int size(); //返回Map里key-value的个数
Collection<V> values(); //返回该Map里所有value组成的Collection
boolean equals(Object o);
int hashCode();
default V getOrDefault(Object key, V defaultValue){...}; //获取指定key对应的value,如果该key不存在,则返回defaulrValue
default void forEach(BiConsumer<? super K, ? super V> action){...}; //使用这个新的API能方便的遍历集合中的元素,这个方法的使用需要结合Lambda表达式:map.forEach((k, v) -> System.out.println("key=" + k + ", value=" + v))
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function){...};//该方法使用BiFunction对原key-value对进行计算,并将计算结果作为该key-value对的value值。
default V putIfAbsent(K key, V value){...}; //该方法会自动检测指定key对应的value是否为null,如果该key对应的value为null,该方法会用新的value代替原来的null值。调用putIfAbsent会直接插入
default V replace(K key, V value){...}; //将Map中指定key对应的value替换成新value。
default boolean replace(K key, V oldValue, V newValue){...}; //将Map中指定key-value对应的原value替换成新value。如果找到则替换,否则返回false
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction){...}; //如果传给该方法的key参数在Map中对应的value为null,则使用mappingFunction根据key计算一个新的结果,如果计算结果不为null,则用计算结果覆盖原有的value.如果原Map原来不包含该key,该方法将会添加一组key-value对。
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction){...}; //如果传给该方法的key参数在Map中对应的value为null,则使用remappingFunction根据原key,value计算一个新的结果.如果计算结果不为null,则使用该结果覆盖原来的value;如果计算结果为null,则删除原key-value对。
default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction){...}; //该方法使用remappingFunction根据原有key-value计算一个新的value.只要新的value不为null,就使用新value覆盖原value;如果原value不为null,但是新value为null,则删除原key-value对;如果原value,新value同时为null,那么直接返回null
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction){...}; //该方法会根据key参数获取在该Map中对应的value。如果获取的value为null,则直接用传入的value覆盖原来的value;如果获取的value不为null,则使用remappingFunction函数根据原value,新value计算一个新的结果,并用得到的结果去覆盖原有的value.
我们来看一下Map接口中的内部接口Entry源码,其封装了一个key-value对:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
interface Entry<K,V>{
K getKey(); //返回该Entry里包含的key值
V getValue(); //返回该Entry里包含的value值
V setValue(); //设置该Entry里包含的value值,并返回新设置的value值
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey(){
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。在介绍这三个之前,我们先来了解一下Map的抽象类AbstractMap。
1.2.1 AbstractMap源码解析
AbstractMap抽象类实现了一些简单且通用的方法,本身并不难。但在这个抽象类中有两个方法非常值得关注,keySet和values方法源码的实现可以说是教科书式的典范。Java中Map类型的数据结构有相当多,AbstractMap作为它们的骨架实现实现了Map接口部分方法,也就是说为它的子类各种Map提供了大部分公共的方法,它的子类只需要实现Set<Entry<K,V» entrySet() 返回一个键值对的集合,就可以使用Map集合的功能了。
抽象类不能通过new关键字直接创建抽象类的实例,但它可以有构造方法。AbstractMap提供了一个protected修饰的无参构造方法,意味着只有它的子类才能访问(当然它本身就是一个抽象类,其他类也不能直接对其实例化),也就是说只有它的子类才能调用这个无参的构造方法。
AbstractMap中唯一的抽象方法:
1
public abstract Set<Entry<K,V>> entrySet();
当我们要实现一个不可变的Map时,只需要继承这个类,然后实现entrySet()方法,这个方法返回一保存所有key-value映射的set。通常这个set不支持add(),remove()方法,Set对应的迭代器也不支持remove()方法。
如果想要实现一个可变的Map,我们需要在上述操作外,重写put()方法,因为默认不支持put操作:
1
2
3
public V put(K key, V value) {
throw new UnsupportedOperationException();
}
而且 entrySet() 返回的 Set 的迭代器,也得实现 remove() 方法,因为 AbstractMap 中的 删除相关操作都需要调用该迭代器的 remove() 方法。
AbstractMap的成员变量
1
2
3
4
5
6
/**
* keySet和values是lazy的,它们只会在第一次请求视图时进行初始化,
* 而且它们是无状态的,所以只需要一个实例(初始化一次)。
*/
transient Set<K> keySet; //保存map中所有的键的Set
transient Collection<V> values; //保存map中所有值的集合
注意:这两个成员变量都是被transient修饰的,从jdk1.8开始,这两个变量不再使用volatile修饰,因为调用这两个变量的方法不是同步的,增加volatile也不能保证线程安全。
AbstractMap的成员方法
AbstractMap中实现了许多方法,接下来来具体看看AbstractMap中的方法。
1.添加方法
1
2
3
public V put(K key, V value) {
throw new UnsupportedOperationException();
}
直接抛出异常,如果子类不复写这个方法,那么它是一个不可修改的Map集合。
1
2
3
4
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
遍历Map集合m,通过它的entrySet()方法得到可迭代的Set集合,然后将每个键值对存放到本Map集合中。
2.删除方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public V remove(Object key) {
//获取键值对的迭代器
Iterator<Entry<K,V>> i = entrySet().iterator();
Entry<K,V> correctEntry = null;
// 根据key是否为null,分成两部分,虽然这两部分代码逻辑几乎一样
// 这样做主要是减少判断,因为合成一部分的话,判断条件就要增加
if (key==null) {
while (correctEntry==null && i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
correctEntry = e;
}
} else {
while (correctEntry==null && i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
correctEntry = e;
}
}
V oldValue = null;
//如果找到了这个键值对correctEntry,删除它,并返回它的value值
if (correctEntry !=null) {
oldValue = correctEntry.getValue();
i.remove();
}
return oldValue;
}
通过entrySet().iterator()方法,得到键值对的迭代器,然后遍历键值对,找到与key值相等的键值对,删除它,并返回对应的value值,如果没找到,就返回null。
1
2
3
public void clear() {
entrySet().clear();
}
调用entrySet集合的clear()方法。
3.查找元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean containsKey(Object key) {
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return true;
}
}
return false;
}
通过entrySet().iterator()方法,得到键值对的迭代器,然后遍历键值对,找到与key值相等的键值对,返回true,否则返回false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean containsValue(Object value) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (value==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getValue()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (value.equals(e.getValue()))
return true;
}
}
return false;
}
通过entrySet().iterator()方法,得到键值对的迭代器,然后遍历键值对,找到与value值相等的键值对,返回true,否则返回false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public V get(Object key) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return e.getValue();
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return e.getValue();
}
}
return null;
}
通过entrySet().iterator()方法,得到键值对的迭代器,然后遍历键值对,找到与key值相等的键值对,并返回对应的value值,如果没找到,就返回null。
4.获取主要的视图
AbstractMap没有提供entrySet()的实现,但是却提供了keySet()与values()集合视图的默认实现,它们都是依赖于entrySet()返回的集合视图实现的,首先我们来了解一下public Set<J>keySet():
分析:该方法返回Map key值的Set集合,很自然的我们可以想到一个简单的实现方案,遍历Entry数组取出key值放到Set集合中,类似下面代码:
1
2
3
4
5
6
7
8
//示例代码
public Set<K> keySet() {
Set<K> ks = null;
for (Map.Entry<K, V> entry : entrySet()) {
ks.add(entry.getKey());
}
return ks;
}
这就意味着每次调用keySet方法都会遍历Entry数组,数据量大时效率会大大降低。不得不说JDK源码是写得非常好,它并没有采取遍历的方式。如果不遍历Entry,那又如何知道此时Map新增了一个key-value键值对呢?
答案就是在keySet方法内部重新实现了一个新的自定义Set集合,在这个自定义Set集合中又重写了iterator方法,这里是关键,iterator方法返回Iterator接口,而在这里又重新实现了Iterator迭代器,通过调用entrySet方法再调用它的iterator方法。下面结合代码来分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
/**
* keySet和values是lazy的,它们只会在第一次请求视图时进行初始化,
* 而且它们是无状态的,所以只需要一个实例(初始化一次)。
*/
transient Set<K> keySet; //保存map中所有的键的Set
transient Collection<V> values; //保存map中所有的value的Collection
public Set<K> keySet() {
Set<K> ks = keySet; //使用keySet变量做缓存,这样只有第一次需要遍历entrySet()集合,对它的操作都调用Map集合对应方法
if (ks == null) {
ks = new AbstractSet<K>() { //创建一个自定义Set
public Iterator<K> iterator() {
// 创建一个迭代器,利用 entrySet().iterator()的迭代器来实现本Iterator实例的方法
return new Iterator<K>() {
private Iterator<Entry<K,V>> i = entrySet().iterator();
public boolean hasNext() {
return i.hasNext(); //对key值的判断,就是对entry的判断
}
public K next() {
return i.next().getKey(); //取下一个key值,就是取entry#getKey
}
public void remove() {
i.remove(); //删除key值,就是删除entry
}
};
}
public int size() {
//key值有多少就是整个Map有多大,所以调用本类的size方法即可。这个是内部类,直接使用this关键字代表这个类,应该指明是调用AbstractMap中的size方法,没有this则表示是static静态方法
return AbstractMap.this.size();
}
public boolean isEmpty() {
//对是否有key值,就是判断Map是否为空,,所以调用本类的isEmpty方法即可
return AbstractMap.this.isEmpty();
}
public void clear() {
//清空key值,就是清空Map,,所以调用本类的clear方法即可
AbstractMap.this.clear();
}
public boolean contains(Object k) {
//判断Set是否包含数据k,就是判断Map中是否包含key值,所以调用本类的containsKey方法即可
return AbstractMap.this.containsKey(k);
}
};
keySet = ks;
}
return ks;
}
这是一种很巧妙的实现,尽管这个方法是围绕key值,但实际上可以结合Entry来实现,而不用遍历Entry,同时上面提到了调用entrySet# iterator方法,这里则又是模板方法模式的最佳实践。因为entrySet在AbstractMap中并未实现,而是交给了它的子类去完成,但是对于keySet方法却可以对它进行一个“算法骨架” 实现,这就是模板方法模式。
下面来看看values()方法的具体实现,其实该方法完全可以参考keySet(),两者有异曲同工之妙,唯一的区别就是返回的是AbstractCollection的子类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
transient Set<K> keySet; //保存map中所有的键的Set
transient Collection<V> values; //保存map中所有的value的Collection
public Collection<V> values() {
// 使用values变量做缓存用的,防止每次都遍历创建
Collection<V> vals = values;
if (vals == null) {
// 创建一个Collection集合,对它的操作都调用Map集合对应方法。
vals = new AbstractCollection<V>() {
public Iterator<V> iterator() {
// 创建一个迭代器,利用 entrySet().iterator()的迭代器来实现本Iterator实例的方法。
return new Iterator<V>() {
private Iterator<Entry<K,V>> i = entrySet().iterator();
public boolean hasNext() {
return i.hasNext();
}
public V next() {
return i.next().getValue();
}
public void remove() {
i.remove();
}
};
}
public int size() {
return AbstractMap.this.size();
}
public boolean isEmpty() {
return AbstractMap.this.isEmpty();
}
public void clear() {
AbstractMap.this.clear();
}
public boolean contains(Object v) {
return AbstractMap.this.containsValue(v);
}
};
values = vals;
}
return vals;
}
5.AbstractMap中的内部类
正如 Map 接口 中有内部类 Map.Entry 一样, AbstractMap 也有两个内部类:
- SimpleImmutableEntry, 表示一个不可变的键值对;
- SimpleEntry, 表示可变的键值对。
SimpleImmutableEntry,不可变的键值对,实现了 Map.Entry <K,V> 接口和Serializable接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
private static boolean eq(Object o1, Object o2) {
return o1 == null ? o2 == null : o1.equals(o2);
}
public static class SimpleImmutableEntry<K,V>
implements Entry<K,V>, java.io.Serializable
{
private static final long serialVersionUID = 7138329143949025153L;
private final K key; //final修饰,不可变
private final V value; //final修饰,不可变
public SimpleImmutableEntry(K key, V value) {
this.key = key;
this.value = value;
}
public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) {
this.key = entry.getKey();
this.value = entry.getValue();
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
// 因为是不可修改键值对Entry类,所以setValue方法直接抛出异常
public V setValue(V value) {
throw new UnsupportedOperationException();
}
// 当key值与value值都相等时,就说明两个entry值相等
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o; // 因为泛型编译时会被擦除,所以使用?号
return eq(key, e.getKey()) && eq(value, e.getValue());
}
// 保证两个相等的entry,它们的hashCode值必须也相同
public int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
public String toString() {
return key + "=" + value;
}
}
SimpleEntry, 可变的键值对:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
public static class SimpleEntry<K,V>
implements Entry<K,V>, java.io.Serializable
{
private static final long serialVersionUID = -8499721149061103585L;
private final K key; //不可变
private V value;
public SimpleEntry(K key, V value) {
this.key = key;
this.value = value;
}
public SimpleEntry(Entry<? extends K, ? extends V> entry) {
this.key = entry.getKey();
this.value = entry.getValue();
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
// 替换value值,并返回原来的oldValue值
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
// 当key值与value值都相等时,就说明两个entry值相等
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return eq(key, e.getKey()) && eq(value, e.getValue());
}
public int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
public String toString() {
return key + "=" + value;
}
}
6.总结
和 AbstractCollection 接口,AbstractList 接口 作用相似, AbstractMap 是一个基础实现类,实现了 Map 的主要方法,默认不支持修改。常用的几种 Map, 比如 HashMap, TreeMap, LinkedHashMap 都继承自它。
- AbstractMap的核心方法是entrySet(),子类必须实现;
- Entry是存储键值对的数据结构,子类根据Map的特点,构造不同的Entry。
1.2.2 HashMap源码解析(JDK 1.7)
在讨论HashMap具体实现之前,我想我们先了解一下其他数组结构在新增、查找等基础操作时的执行性能:
- 数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)。
- 线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)。
- 二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
- 哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置=f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:

然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap在JDK 1.7中就是采用了链地址法,也就是数组+链表的方式。(在Java 1.8中采用了数组+链表+红黑树的方式)
下面我们先来分析JDK 1.7版本的HashMap源码:
参考文章:
1.类定义
1
2
3
4
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable

2.数据结构
HashMap采用的数据结构是:数组(主)+单链表(副),该数据结构描述又被称之为拉链法:
对于数组(主),其主要的作用如下:
- 核心底层 = 1个数组(table[]),其又被称之为核心数组;
- 数组下标 = 经过处理的键Key的hash值(通过hashCode() 计算等一系列处理)
- 数组元素 = 1个键值对 = 1个链表(头节点)
- 数组大小 = HashMap的容量 (capacity)
而对于单链表(副):
- 每个链表 = 哈希表的桶(bucket)
- 链表的节点值 = 1个键值对
- 链表长度 = 桶的大小
- 链表主要是用于解决哈希冲突:若是不同key值计算出来的hash值相同(即都存储到了数组的相同位置),由于之前该hash值的数组位置已经存放好元素,则将原先位置的元素移到单链表中,冲突hash值对应的键值对放入到数组元素中。(即发生冲突时,新元素插入到链表头部;新元素总是添加到数组中,旧元素移到链表中)
- 采用链表解决hash冲突的方法 = 链地址法
Attention: HashMap的键值对数量 = 数组的键值对 + 所有单链表的键值对
给出示意图如下所示:

给出粗略的存储流程如下:

数组元素、链表节点的实现类
HashMap中的数组元素采用Entry静态内部类实现,如下所示:

- HashMap的本质 = 1个存储Entry类对象的数组 + 多个单链表
- Entry对象本质 = 1个映射(键 - 值对),属性包括:键(key)、值(value) & 下1节点( next) = 单链表的指针 = 也是一个Entry对象,用于解决hash冲突
给出该类的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; //键
V value; // 值
Entry<K,V> next; // 指向下一个节点 ,也是一个Entry对象,从而形成解决hash冲突的单链表
int hash; //对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//作用:判断2个Entry是否相等,必须key和value都相等,才返回true
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
3.HashMap中的重要变量
主要参数其实包括: 容量、负载因子和扩容阈值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// 1. 容量(capacity): HashMap中数组的长度
// a. 容量范围:必须是2的幂 & <最大容量(2的30次方)
// b. 初始容量 = 哈希表创建时的容量
// 默认容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大的容量,为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
// 2. 负载因子(Load factor):HashMap在其容量自动增加前可达到多满的一种尺度
// a. 负载因子越大、填满的元素越多 = 空间利用率高、但冲突的机会加大、查找效率变低(因为链表变长了)
// b. 负载因子越小、填满的元素越少 = 空间利用率小、冲突的机会减小、查找效率高(链表不长)
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//实际加载因子
final float loadFactor;
//当数组还没有进行扩容操作的时候,共享的一个空表对象
static final Entry<?,?>[] EMPTY_TABLE = {};
//table,进行扩容操作,长度必须2的n次方
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//HashMap的大小,即 HashMap中存储的键值对的数量
transient int size;
// 3. 扩容阈值(threshold):当哈希表的大小 ≥ 扩容阈值时,就会扩容哈希表(即扩充HashMap的容量)
// a. 扩容 = 对哈希表进行resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数
// b. 扩容阈值 = 容量 x 加载因子
//阈值,用于判断是否需要扩容(threshold = 容量*负载因子)
int threshold;
//HashMap改变的次数
transient int modCount;
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;

详细地介绍一下负载因子的使用建议:

4.源码分析
为了更具体的了解源码,从具体的使用步骤进行相关函数的详细分析,其主要内容如下所示:

1. 构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
//指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor; //设置加载因子
// 设置 扩容阈值 = 初始容量
// 注:此处不是真正的阈值,是为了扩展table,该阈值后面会重新计算,下面会详细讲解
threshold = initialCapacity;
init(); // 一个空方法用于未来的子对象扩展
}
// 指定“容量大小”的构造函数,加载因子 = 默认 = 0.75 、容量 = 指定大小
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 构造函数1:默认构造函数(无参)
* 加载因子 & 容量 = 默认 = 0.75、16
*/
public HashMap() {
// 实际上是调用构造函数3:指定“容量大小”和“加载因子”的构造函数
// 传入的指定容量 & 加载因子 = 默认
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
// 包含“子Map”的构造函数,即 构造出来的HashMap包含传入Map的映射关系
// 加载因子 & 容量 = 默认
public HashMap(Map<? extends K, ? extends V> m) {
// 设置容量大小 & 加载因子 = 默认
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 该方法用于初始化 数组 & 阈值,下面会详细说明
inflateTable(threshold);
// 将传入的子Map中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
注意:
- 此处仅用于接收初始容量大小(capacity)、加载因子(Load factor),但仍无真正初始化哈希表,即初始化存储数组table;
- 真正初始化哈希表(初始化存储数组table)是在第1次添加键值对时,即第1次调用put()时。下面会详细说明。
2. put()方法的解析
给出一个添加数据的流程图:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public V put(K key, V value) {
// (分析1) 1.若未初始化哈希表,即table为空
// 则使用构造函数设置的阈值(即初始容量)来初始化数组table
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//(分析2) 2.判断key是否为空值null
// 2.1 若key == null,则将该键-值 存放到数组table 中的第1个位置,即table [0](本质:key = Null时,hash值 = 0,故存放到table[0]中)
// 该位置永远只有1个value,新传进来的value会覆盖旧的value
if (key == null)
return putForNullKey(value);
// (分析3) 2.2 若 key ≠ null,则计算存放数组 table 中的位置(下标、索引)
// a. 根据key值计算hash值
int hash = hash(key);
// b. 根据hash值 最终获得key对应存放的数组Table中位置
int i = indexFor(hash, table.length);
// 3. 判断该key对应的值是否已存在(通过遍历 以该数组元素为头结点的链表 逐个判断)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// (分析4) 3.1 若该key已存在(即 key-value已存在 ),则用 新value 替换 旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧的value
}
}
modCount++;
//(分析5) 3.2 若 该key不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
return null;
}
根据源码做出相对应的流程图如下:

下面针对源码里标明的5个分析点进行详细解释:
- 初始化哈希表(即初始化数组table, 扩容阈值)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
//函数使用原型
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//源码分析
private void inflateTable(int toSize) {
// 将传入的容量大小转化为:>传入容量大小的最小的2的次幂,即如果传入的是容量大小是19,那么转化后,初始化容量大小为32(即2的5次幂)
int capacity = roundUpToPowerOf2(toSize);
//重新计算阈值 threshold = 容量 * 加载因子
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 使用计算后的初始容量(已经是2的次幂) 初始化数组table(作为数组长度),即 哈希表的容量大小 = 数组大小(长度)
table = new Entry[capacity];
//修改hashSeed
initHashSeedAsNeeded(capacity);
}
// 将传入的容量大小转化为:>传入容量大小的最小的2的幂
// 特别注意:容量大小必须为2的幂,该原因在下面的讲解会详细分析
private static int roundUpToPowerOf2(int number) {
// 若 容量超过了最大值,初始化容量设置为最大值 ;否则,设置为:>传入容量大小的最小的2的次幂
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
// 与虚拟机设置有关,改变hashSeed的值
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0;
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
通过上面分析可以看出:真正初始化哈希表(初始化存储数组table)是在第1次添加键值对时,即第1次调用put()时。
- 当 key == null时,将该 key-value 的存储位置规定为数组table 中的第1个位置,即table [0].
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
//函数使用原型
if (key == null)
return putForNullKey(value);
// 源码分析
private V putForNullKey(V value) {
// 遍历以table[0]为首的链表,寻找是否存在key==null 对应的键值对
// 1. 若有:则用新value 替换 旧value;同时返回旧的value值
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 2. 若无key==null的键,那么调用addEntry(),将空键 & 对应的值封装到Entry中,并放到table[0]中
addEntry(0, null, value, 0);
// 注:
// a. addEntry()的第1个参数 = hash值 = 传入0
// b. 即 说明:当key = null时,也有hash值 = 0,所以HashMap的key 可为null
// c. 对比HashTable,由于HashTable对key直接hashCode(),若key为null时,会抛出异常,所以HashTable的key不可为null
// d. 此处只需知道是将 key-value 添加到HashMap中即可,关于addEntry()的源码分析将等到下面再详细说明,
return null;
}
从此处可以看出:
- HashMap的键key 可为null(区别于 HashTable的key 不可为null);
- HashMap的键key 可为null且只能为1个,但值value可为null且为多个
- 计算存放数组 table 中的位置(即 数组下标 or 索引)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//函数使用原型
int hash = hash(key); // a. 根据键值key计算hash值 ->> 分析1
int i = indexFor(hash, table.length); // b. 根据hash值 最终获得 key对应存放的数组Table中位置 ->> 分析2
//源码分析
//将 键key 转换成 哈希码(hash值)操作 = 使用hashCode() + 4次位运算 + 5次异或运算(9次扰动)
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //将对哈希码扰动处理后的结果 与运算(&) (数组长度-1),最终得到存储在数组table的位置(即数组下标、索引)
}

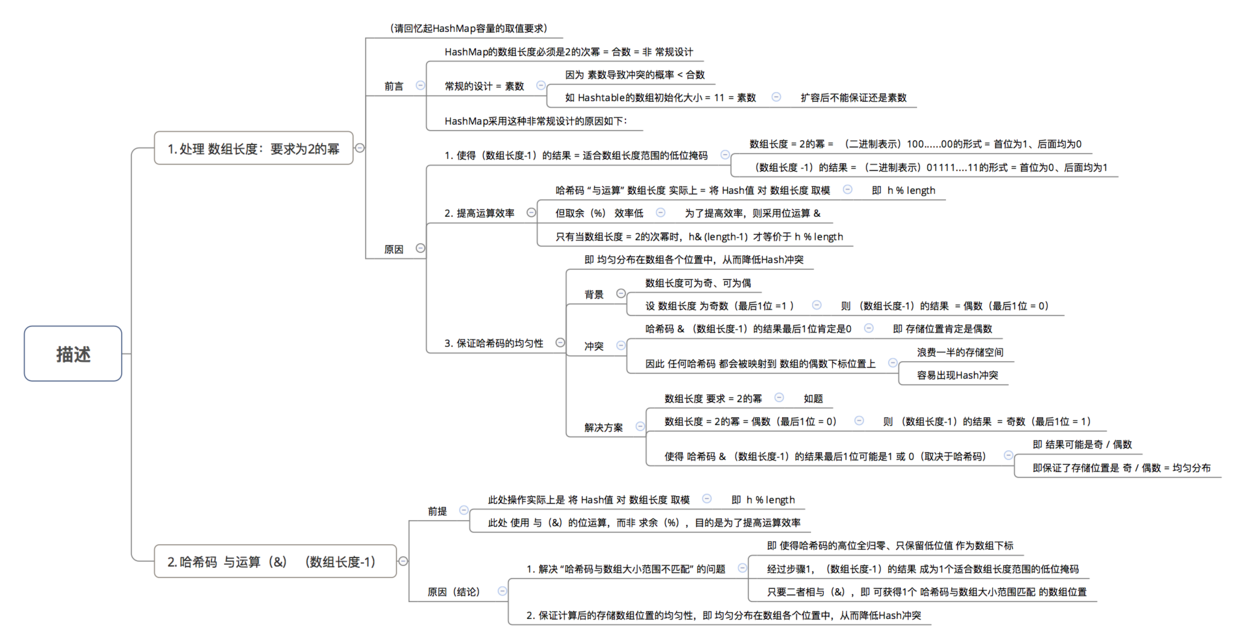
在了解了如何计算存放数组table 中的位置 后,所谓知其然而需知其所以然,下面将讲解为什么要这样计算,即主要解答以下3个问题:
- 为什么不直接采用经过hashCode()处理的哈希码 作为存储数组table的下标位置?
- 为什么采用哈希码 与运算(&) (数组长度-1) 计算数组下标?
- 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
在回答这3个问题前,有一个核心思想需要了解:
所有处理的根本目的,都是为了提高 存储key-value的数组下标位置 的随机性 & 分布均匀性,尽量避免出现hash值冲突。即:对于不同key,存储的数组下标位置要尽可能不一样。
问题1:为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
这是因为如果采用这种方式,容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置。

为了解决 “哈希码与数组大小范围不匹配” 的问题,HashMap给出了解决方案:哈希码 与运算(&) (数组长度-1)。
问题2: 为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
根据HashMap的容量大小(数组长度),按需取 哈希码一定数量的低位 作为存储的数组下标位置,从而 解决 “哈希码与数组大小范围不匹配” 的问题

上图同时也给出了为什么HashMap的数组长度一定是2的次幂问题的解答,其实还有一个原因,将在后面具体讲述。
问题3: 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
该操作是为了加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突。

- 若对应的key已存在,则 使用 新value 替换 旧value
当发生 Hash冲突时,为了保证 键key的唯一性哈希表并不会马上在链表中插入新数据,而是先查找该 key是否已存在,若已存在,则替换即可.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/**
* 函数使用原型
*/
// 2. 判断该key对应的值是否已存在(通过遍历 以该数组元素为头结点的链表 逐个判断)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 2.1 若该key已存在(即 key-value已存在 ),则用 新value 替换 旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; //并返回旧的value
}
}
modCount++;
// 2.2 若 该key不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
return null;
此处无复杂的源码分析,但此处的分析点主要有2个:替换流程 & key是否存在(即key值的对比)
替换流程

key值的对比
采用 equals() 或 “==” 进行比较,下面给出其介绍 equals() 与 “==”使用的对比:

- 若对应的key不存在,则将该“key-value”添加到数组table的对应位置中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
//函数使用原型
2.2 若 该key不存在,则将“key-value”添加到table中
addEntry(hash, key, value, i);
//源码解析
void addEntry(int hash, K key, V value, int bucketIndex) {
// 1.插入前,先判断容量是否足够
// 1.1 若不足够,则进行扩容(2倍)、重新计算Hash值、重新计算数组存储下标
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // a.扩容两倍 --》分析1
hash = (null != key) ? hash(key) : 0; // b. 重新计算该Key对应的Hash值
bucketIndex = indexFor(hash, table.length); // c. 重新计算该Key对应的hash值的存储数组下标位置
}
// 1.2 若容量足够,则创建1个新的数组元素(Entry) 并放入到数组中 --》 分析2
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
//1.保存旧数组(old table)
Entry[] oldTable = table;
//2.保存旧容量(old capacity ),即数组长度
int oldCapacity = oldTable.length;
//3.若旧容量已经是系统默认最大容量了,那么将阈值设置成整型的最大值,退出
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 4. 根据新容量(2倍容量)新建1个数组,即新table
Entry[] newTable = new Entry[newCapacity];
// 5. 将旧数组上的数据(键值对)转移到新table中,从而完成扩容 ->>分析1.1
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 6. 新数组table引用到HashMap的table属性上
table = newTable;
// 7. 重新设置阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 分析1.1:transfer(newTable);
* 作用:将旧数组上的数据(键值对)转移到新table中,从而完成扩容
* 过程:按旧链表的正序遍历链表、在新链表的头部依次插入
*/
void transfer(Entry[] newTable, boolean rehash) {
// 获取新数组的大小 = 获取新容量大小
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //通过遍历 旧数组,将旧数组上的数据(键值对)转移到新数组中
while(null != e) {
Entry<K,V> next = e.next; //遍历 以该数组元素为首 的链表,转移链表时,因是单链表,故要保存下1个结点,否则转移后链表会断开
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
// 扩容后,可能出现逆序:按旧链表的正序遍历链表、在新链表的头部依次插入
e.next = newTable[i];
newTable[i] = e;
// 访问下1个Entry链上的元素,如此不断循环,直到遍历完该链表上的所有节点
e = next;
}
}
}
// 若容量足够,则创建1个新的数组元素(Entry) 并放入到数组中
void createEntry(int hash, K key, V value, int bucketIndex) {
// 把table中该位置原来的Entry保存
Entry<K,V> e = table[bucketIndex];
// 2. 在table中该位置新建一个Entry:将原头结点位置(数组上)的键值对 放入到(链表)后1个节点中、将需插入的键值对 放入到头结点中(数组上)-> 从而形成链表
// 即 在插入元素时,是在链表头插入的,table中的每个位置永远只保存最新插入的Entry,旧的Entry则放入到链表中(即 解决Hash冲突)
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
此处有2点需要特别注意的:键值对的添加方式与扩容机制
键值对的添加方式:单链表的头插法
即将该位置(数组上)原来的数据放在该位置的(链表)下1个节点中(next)、在该位置(数组上)放入需插入的数据-> 从而形成链表。

扩容机制
来看一下具体流程:

扩容过程中的转移数据示意图:

在扩容resize()过程中,在将旧数组上的数据 转移到 新数组上时,转移操作 = 按旧链表的正序遍历链表、在新链表的头部依次插入,即在转移数据、扩容后,容易出现链表逆序的情况.
设重新计算存储位置后不变,即扩容前 = 1->2->3,扩容后 = 3->2->1
此外,此时若(多线程)并发执行 put()操作,一旦出现扩容情况,则容易出现环形链表,从而在获取数据、遍历链表时形成死循环(Infinite Loop)。在此,就直接给出为什么HashMap是线程不安全的原因:
put的时候导致的多线程数据不一致。这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。多线程并发执行put()操作时,可能因为resize()操作出现环形链表,从而引起死循环。
给出形成环形链表的具体分析流程:

我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,后面继续遍历那么就会陷入死循环。
前面提到HashMap的数组长度为什么一定是2的次幂的一些原因,其实在resize这里还有另外一种解释:
hashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。从下图可以我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换)

还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀,比如:

我们看到,上面的&运算,高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=21这个存储位置,h的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。

如果不是2的次幂,也就是低位不是全为1此时,要使得index=21,h的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
- 总结
向 HashMap 添加数据(成对 放入 键 - 值对)的全流程:

示意图:

3. get()方法的解析
给出get()方法的流程如下:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public V get(Object key) {
if (key == null) // 1.当key == null时,则到 以哈希表数组中的第1个元素(即table[0])为头结点的链表去寻找对应 key == null的键
return getForNullKey(); //分析1
// 2. 当key ≠ null时,去获得对应值 -->分析2
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
// 当key == null时,则到 以哈希表数组中的第1个元素(即table[0])为头结点的链表去寻找对应 key == null的键
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
// 1. 根据key值,通过hash()计算出对应的hash值
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) { // 遍历 以该数组下标的数组元素为头结点的链表所有节点,寻找该key对应的值
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
4. 其他常用方法的解析
HashMap除了核心的put()、get()函数,还有以下主要使用的函数方法:
1
2
3
4
5
6
7
8
9
void clear(); // 清除哈希表中的所有键值对
int size(); // 返回哈希表中所有 键值对的数量 = 数组中的键值对 + 链表中的键值对
boolean isEmpty(); // 判断HashMap是否为空;size == 0时 表示为 空
void putAll(Map<? extends K, ? extends V> m); // 将指定Map中的键值对 复制到 此Map中
V remove(Object key); // 删除该键值对
boolean containsKey(Object key); // 判断是否存在该键的键值对;是 则返回true
boolean containsValue(Object value); // 判断是否存在该值的键值对;是 则返回true
下面将简单介绍上面几个函数的源码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
/**
* 函数:isEmpty()
* 作用:判断HashMap是否为空,即无键值对;size == 0时 表示为 空
*/
public boolean isEmpty() {
return size == 0;
}
/**
* 函数:size()
* 作用:返回哈希表中所有 键值对的数量 = 数组中的键值对 + 链表中的键值对
*/
public int size() {
return size;
}
/**
* 函数:clear()
* 作用:清空哈希表,即删除所有键值对
* 原理:将数组table中存储的Entry全部置为null、size置为0
*/
public void clear() {
modCount++;
Arrays.fill(table, null);
size = 0;
}
/**
* 函数:putAll(Map<? extends K, ? extends V> m)
* 作用:将指定Map中的键值对 复制到 此Map中
* 原理:类似Put函数
*/
public void putAll(Map<? extends K, ? extends V> m) {
// 1. 统计需复制多少个键值对
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
// 2. 若table还没初始化,先用刚刚统计的复制数去初始化table
if (table == EMPTY_TABLE) {
inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
}
// 3. 若需复制的数目 > 阈值,则需先扩容
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
// 4. 开始复制(实际上不断调用Put函数插入)
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
/**
* 函数:remove(Object key)
* 作用:删除该键值对
*/
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
// 1. 计算hash值
int hash = (key == null) ? 0 : hash(key);
// 2. 计算存储的数组下标位置
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
// 若删除的是table数组中的元素(即链表的头结点)
// 则删除操作 = 将头结点的next引用存入table[i]中
if (prev == e)
table[i] = next;
//否则 将以table[i]为头结点的链表中,当前Entry的前1个Entry中的next 设置为 当前Entry的next(即删除当前Entry = 直接跳过当前Entry)
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
/**
* 函数:containsKey(Object key)
* 作用:判断是否存在该键的键值对;是 则返回true
* 原理:调用get(),判断是否为Null
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
/**
* 函数:containsValue(Object value)
* 作用:判断是否存在该值的键值对;是 则返回true
*/
public boolean containsValue(Object value) {
// 若value为空,则调用containsNullValue()
if (value == null)
return containsNullValue();
// 若value不为空,则遍历链表中的每个Entry,通过equals()比较values 判断是否存在
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;//返回true
return false;
}
// value为空时调用的方法
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
5.与JDK1.8的区别
HashMap 的实现在 JDK 1.7 和 JDK 1.8 差别较大,具体区别如下:
1. 数据结构

2.获取数据过程

3.扩容机制

6.关于HashMap的其他问题
1. HashMap如何解决Hash冲突?

2. 为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化?

3.为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键?

4.HashMap 中的 key若 Object类型, 则需实现哪些方法?

1.2.3 HashMap源码分析(JDK 1.8)
HashMap的设计就是为了在查找获得最优的性能(希望基本获取O(1)的时间复杂度),因此HashMap主要使用了数组作为核心的数据存储的结构,同时使用链地址法解决K-V映射时产生的碰撞,在Java8中同时加入红黑树来优化碰撞时数据匹配的性能。下面,我将通过分析源码,讲解HashMap1.8相对应JDK 1.7版本的更新内容。
1.类声明
1
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
HashMap继承自AbstractMap,实现了Map接口,Map接口定义了所有Map子类必须实现的方法。AbstractMap也实现了Map接口,并且提供了两个实现Entry的内部类:SimpleEntry和SimpleImmutableEntry。其具体介绍与JDK 1.7一样。
2.数据结构
主要的数据结构介绍如下:

红黑树(R-B Tree,即Red-Black Tree),是一种特殊的二叉查找树,其主要有以下特点:
- 每个节点的颜色 = 黑色/红色,其根节点为黑色,空叶子节点为黑色;
- 父、子节点必须是不同颜色;
- 从1个节点到该节点的子孙节点的所有路径上包含相同数量的黑色节点。(确保了没有1条路径会比其他路径长出2倍,因此,红黑树是相对接近于平衡二叉树);
- 其时间复杂度为O(log n)。
给出一个粗略的存储流程如下所示:
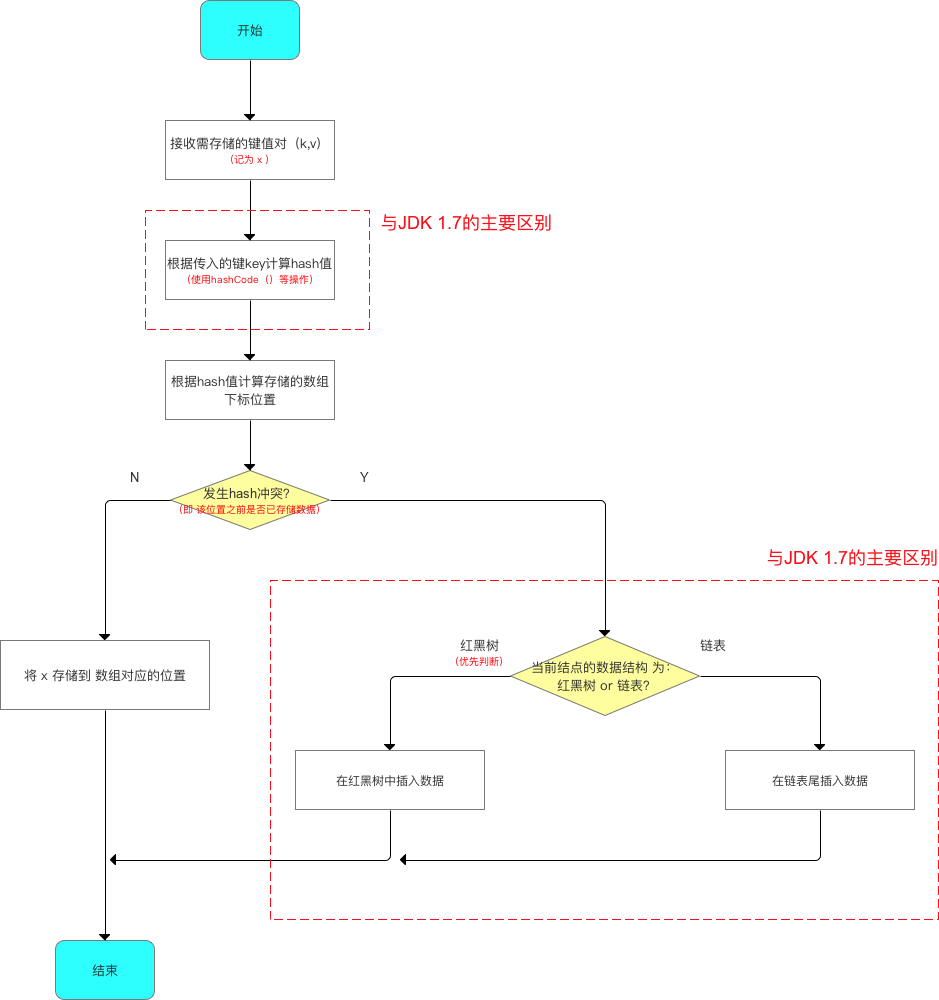
在JDK 1.8中,HashMap中的数组元素与链表节点采用了Node类来实现(1.7中是Entry类,内容没什么变化),给出其源码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/**
* Node = HashMap的内部类,实现了Map.Entry接口,本质是 = 一个映射(键值对)
* 实现了getKey()、getValue()、equals(Object o)和hashCode()等方法
**/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
JDK1.8中引入了红黑树,其在源码中的具体实现类是TreeNode,简略给出源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
...
}
3.HashMap中的重要变量
HashMap中的主要参数与JDK 1.7中大致相同(包含容量、加载因子和扩容阈值)。但是由于其数据结构加入了红黑树,因此也加入了与红黑树相关的属性。具体如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认加载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 存储数据的Node类型 数组,长度 = 2的幂;数组的每个元素 = 1个单链表
*/
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* HashMap中存储的键值对的数量
*/
transient int size;
//HashMap改变的次数
transient int modCount;
// 3. 扩容阈值(threshold):当哈希表的大小 ≥ 扩容阈值时,就会扩容哈希表(即扩充HashMap的容量)
// a. 扩容 = 对哈希表进行resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数
// b. 扩容阈值 = 容量 x 加载因子
int threshold;
//实际加载因子
final float loadFactor;
// 桶的树化阈值:即将链表转成红黑树的阈值,在存储数组时,当链表长度大于该值时,则将链表转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 桶的链表还原阈值:即红黑树转化为链表的阈值,当在扩容时(此时HashMap的数据存储位置会重新计算),在重新计算存储位置后,
// 当原有的红黑树内数量 < 6时,则将红黑树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树形化容量阈值:即当哈希表中的容量大于该值时,才允许树形化链表(即将链表转化为红黑树)
// 否则,若桶内元素太多时,则直接扩容,而不是树形化
// 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4*TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
为此,我们来总结一下HashMap的数据结构与参数在JDK1.8与JDK 1.7之间的异同点:
| 版本 | 存储的数据结构 | 数组&链表节点的实现类 | 红黑树的实现类 | 核心参数 |
|---|---|---|---|---|
| JDK 1.8 | 数组+链表+红黑树 | Node类 | TreeNode类 | 主要参数相同 = 容量、加载因子、扩容阈值。但是JDK1.8增设了与红黑树相关的参数: 1. 桶的树化阈值 即将链表转化为红黑树的阈值,在存储数据时,当链表长度大于该值时,即将链表转换为红黑树 2.桶的链表还原阈值 即将红黑树转为链表的阈值,当在扩容时(此时HashMap的数据存储位置会重新计算),在重新计算存储位置后,当原有的红黑树内数量小于6时,则将红黑树转换成链表 3.最小树形化容量阈值 即当哈希表中的容量大于该值时,才允许树形化链表。否则,若桶内元素太多时,则直接扩容,而不是树形化。为了避免直接扩容、树形化选择的冲突,这个值不能小于4*TREEIFY_THRESHOLD |
| JDK 1.7 | 数组+链表 | Entry类 | / |
4.源码分析
为了更具体的了解源码,从具体的使用步骤进行相关函数的详细分析,其主要内容如下所示:
1.构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
// 构造函数1:指定“容量大小”和“加载因子”的构造函数
// 加载因子 & 容量 = 自己指定
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充比必须为正
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 设置 扩容阈值
// 注:此处不是真正的阈值,仅仅只是将传入的容量大小转化为:>传入容量大小的最小的2的幂,该阈值后面会重新计算
// 下面会详细讲解 ->> 分析1
this.threshold = tableSizeFor(initialCapacity);
}
// 构造函数2:指定“容量大小”的构造函数
// 加载因子 = 默认 = 0.75 、容量 = 指定大小
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 构造函数3: 默认构造函数(无参)
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 构造函数4:包含“子Map”的构造函数
// 即 构造出来的HashMap包含传入Map的映射关系
// 加载因子 & 容量 = 默认
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
// 分析1:tableSizeFor(initialCapacity)
// 作用:将传入的容量大小转化为:>传入容量大小的最小的2的幂
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
同JDK 1.7类似,这里仅用于接收初始容量大小(Capacity)、加载因子(Load Factor),但仍无真正初始化哈希表,即初始化存储数组table。真正初始化哈希表是在第一次添加键值对时,也就是第一次调用put()方法时。
我们来分析一下tableSizeFor()方法,HashMap构造函数允许用户传入的容量不是2的n次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
先来考虑如何求一个数的掩码,对于10010000,它的掩码为11111111,可以使用下面方法得到:
1
2
3
mask = mask >> 1 11011000
mask = mask >> 2 11110110
mask = mask >> 4 11111111
mask+1是大于原始数字的最小的2的n次方。
1
2
num 10010000
mask+1 100000000
综合对比tableSizeFor方法的实现,我们也就能够明白这个方法的功能了。
2.put()方法的解析
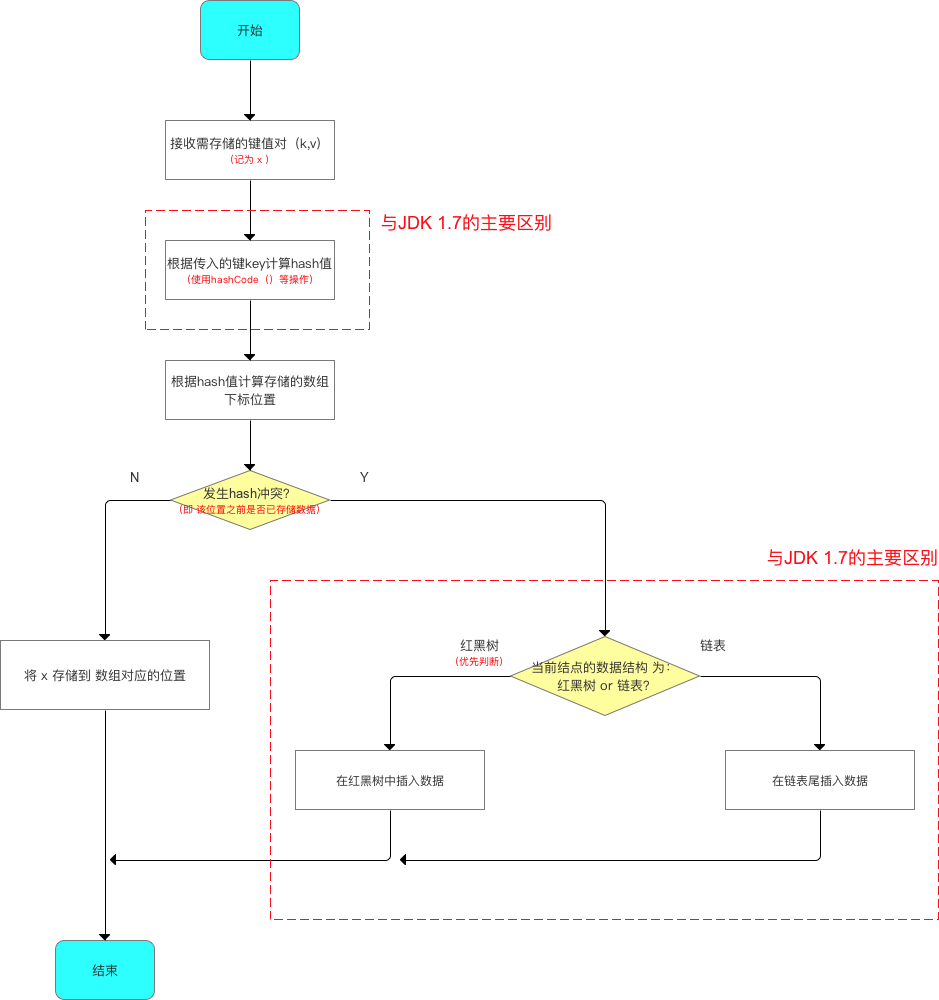
对于该put()方法,其具体实现与JDK 1.7差别较大:

给出一个JDK 1.8的添加数据的简易流程图,如下所示:
1
2
3
4
5
public V put(K key, V value) {
//1. 对传人数组的键key计算hash值 ->> 分析1
//2. 再调用putVal()添加数据进去 ->> 分析2
return putVal(hash(key), key, value, false, true);
}
下面,针对上面的两个分析点进行讲解:
- hash(key):确定哈希桶数组索引位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/**
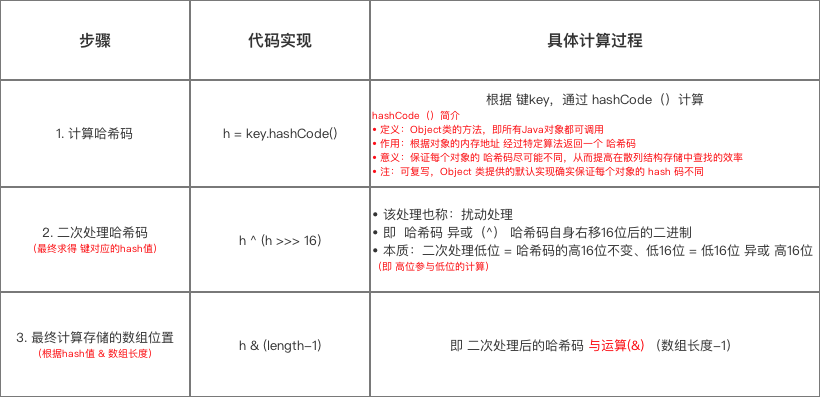
* 分析1:hash(key)
* 作用:计算传入数据的哈希码(哈希值、Hash值)
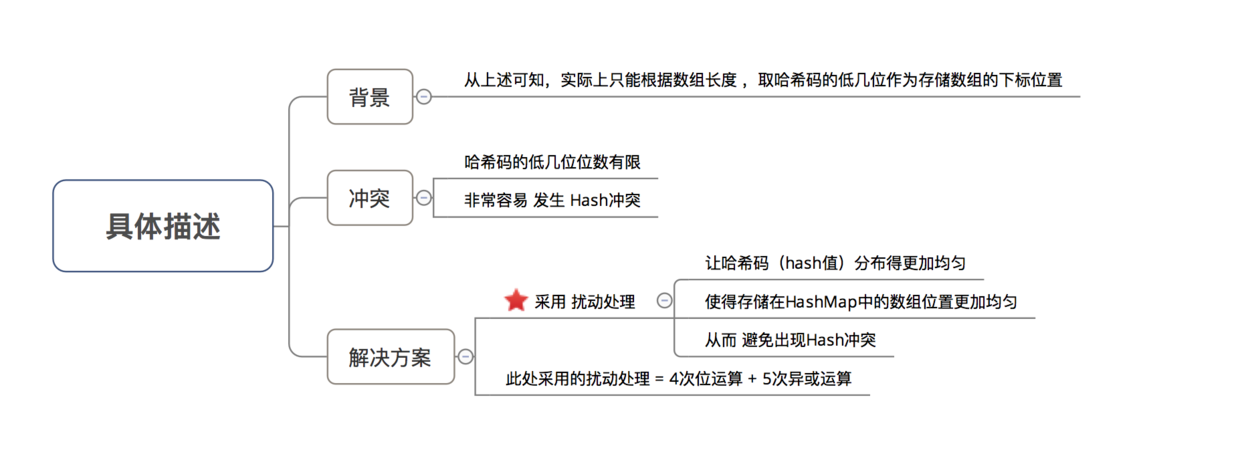
* 该函数在JDK 1.7 和 1.8 中的实现不同,但原理一样 = 扰动函数 = 使得根据key生成的哈希码(hash值)分布更加均匀、更具备随机性,避免出现hash值冲突(即指不同key但生成同1个hash值)
* JDK 1.7 做了9次扰动处理 = 4次位运算 + 5次异或运算
* JDK 1.8 简化了扰动函数 = 只做了2次扰动 = 1次位运算 + 1次异或运算
*/
//JDK 1.8实现:将键key转换成hash值操作 = 使用hashCode() + 1次位运算 + 1次异或运算(2次扰动)
// 1. 取hashCode值: h = key.hashCode()
// 2. 高位参与低位的运算: h ^ (h >>> 16)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
// a. 当key = null时,hash值 = 0,所以HashMap的key 可为null
// 注:对比HashTable,HashTable对key直接hashCode(),若key为null时,会抛出异常,所以HashTable的key不可为null
// b. 当key ≠ null时,则通过先计算出 key的 hashCode()(记为h),然后 对哈希码进行 扰动处理: 按位 异或(^) 哈希码自身右移16位后的二进制
}
//JDK 1.7实现: 将键key转换成哈希码(hash值)操作 = 使用hashCode() + 4次位运算 + 5次异或运算(9次扰动)
static final int hash(int h) {
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* 计算存储位置的函数分析:indexFor(hash, table.length)
* 注:该函数仅存在于JDK 1.7 ,JDK 1.8中实际上无该函数(直接用1条语句判断写出),但原理相同
* 为了方便讲解,故提前到此讲解
*/
static int indexFor(int h, int length) {
// 将对哈希码扰动处理后的结果 与运算(&) (数组长度-1),最终得到存储在数组table的位置(即数组下标、索引)
return h & (length-1);
}
根据上面的源码对比分析,我们来总结一下计算存放在table数组中位置的过程:
在JDK 1.8中优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较下的时候,也能保证考虑到高低位Bit都参与到Hash的计算中,同时不会有很大的开销。下面给出一个例子说明一下:

在了解了如何计算存放数组table 中的位置 后,所谓知其然而需知其所以然,下面将讲解为什么要这样计算,即主要解答以下3个问题:
- 为什么不直接采用经过hashCode()处理的哈希码 作为存储数组table的下标位置?
- 为什么采用哈希码 与运算(&) (数组长度-1) 计算数组下标?
- 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
在回答这3个问题前,有一个核心思想需要了解:
所有处理的根本目的,都是为了提高 存储key-value的数组下标位置 的随机性 & 分布均匀性,尽量避免出现hash值冲突。即:对于不同key,存储的数组下标位置要尽可能不一样。
问题1:为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
这是因为如果采用这种方式,容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置。

问题2: 为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
根据HashMap的容量大小(数组长度),按需取 哈希码一定数量的低位 作为存储的数组下标位置,从而 解决 “哈希码与数组大小范围不匹配” 的问题。
问题3: 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
该操作是为了加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突。
- putVal(hash(key),key,value,false,true)
对于putVal方法,其主要有两个部分需要讲解:其一是计算完存储位置之后,具体该如何将数据存放到哈希表中;其二就是扩容的机制。
2.1计算完存储位置,数据如何存入哈希表中
由于数据结构中加入了红黑树,所以在存放数据到哈希表中时,需要进行多次数据结构的判断:数组、红黑树、链表。下面给出一个具体的判断流程图:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
/**
* 分析2:putVal(hash(key), key, value, false, true)
*/
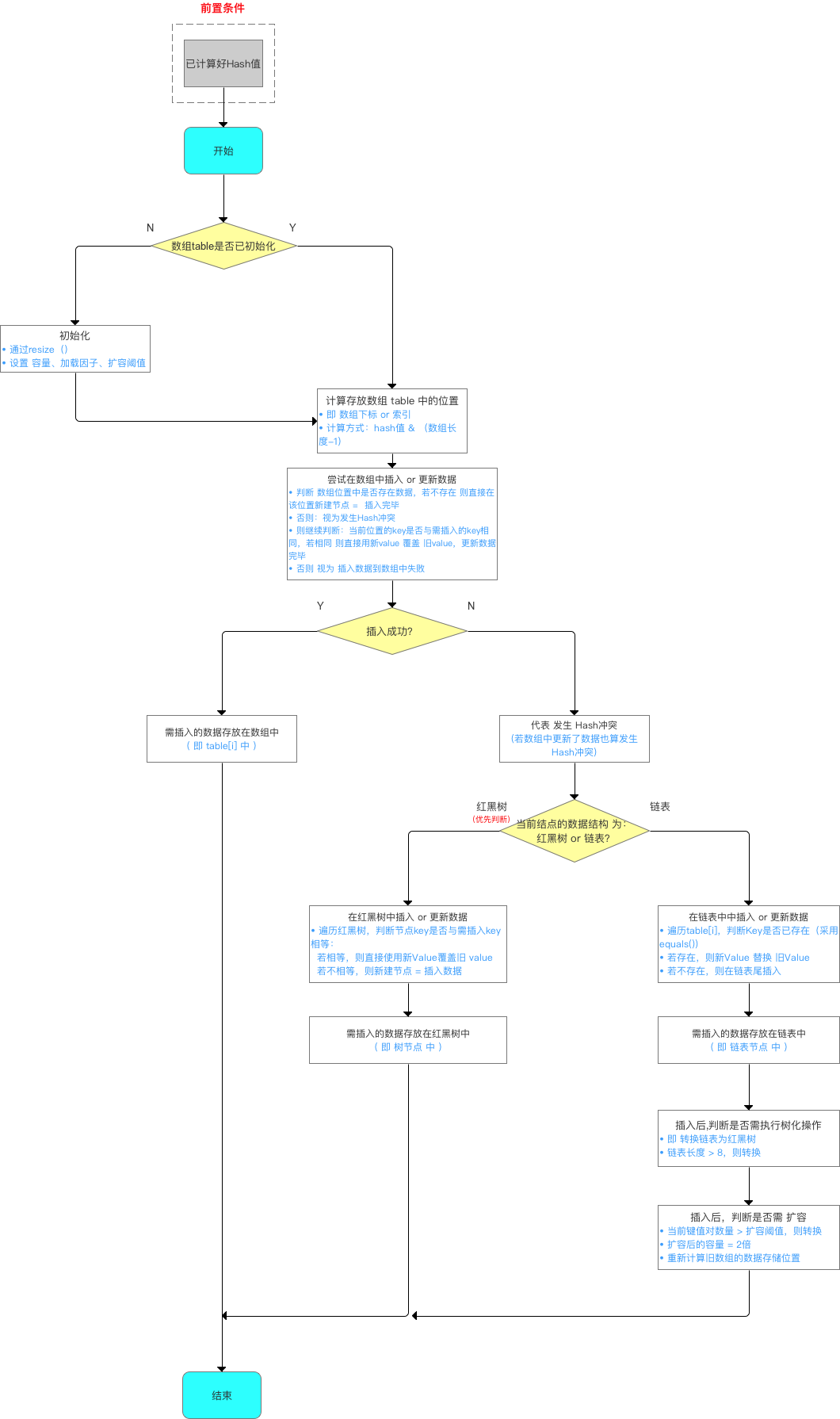
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. 如果哈希表的数组是空,则通过resize()创建。所以,初始化哈希表的时机 = 第1次调用put函数时,即调用resize()初始化创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. 计算插入存储的数组索引i:根据key值计算的hash值得到
// 此处的数组下标计算方式 = i = (n - 1) & hash,同JDK 1.7中的indexFor(),上面已详细描述
//3. 插入时,需要判断hash值是否存在冲突:
// 首先,若不存在(即table[i] == null),则直接在该数组位置新建节点,插入完毕
// 否则,代表存在hash冲突,即当前存储位置已经存在节点,则依次往下判断: a. 当前位置的key是否与需要插入的key相同; b. 判断需要插入的数据结构是否为红黑树或者链表
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 不存在的情况,newNode(hash, key, value, null)的源码 = new Node<>(hash, key, value, next)
else {
Node<K,V> e; K k;
// a.判断table[i]的元素的key是否与插入的key一样,如果相同,则直接用新的value覆盖旧的value,判断原则equals()
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// b. 继续判断:需要插入的数据结构是否为红黑树或者链表
// 如果为红黑树的话,则直接在树中插入 Or 更新键值对
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // ->>分析3
// 若是链表,则在链表中插入 Or 更新键值对
// i. 遍历table[i],判断key是否已经存在:采用equals()对比当前遍历节点的key与需要插入数据的key:若已存在,则直接用新value覆盖旧value
// ii. 遍历完毕后仍无发现上述所说的情况,则直接在链表尾部插入数据
// 但是,注意:新增节点后,需要判断链表长度是否大于8 (8 = 桶的树化阈值) : 若是,则把链表转换为红黑树
else {
for (int binCount = 0; ; ++binCount) {
// 对于ii: 若数组的下一个位置,表示已经到表尾也没有找到key值相同节点,则新建节点 = 插入节点
// 注:此处是从链表尾部插入,与JDK 1.7不同(JDK 1.7是从链表头部插入,即永远都是添加到数组的位置,原来数组位置的数据则往后移)
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 插入节点后,若链表节点大于阈值,则将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //树化操作
break;
}
// 对于i:
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//更新p指向下一个节点,继续遍历
p = e;
}
}
// 对后续情况的操作:发现key已经存在,直接用新value覆盖旧value & 返回旧value
if (e != null) { // existing mapping for key
V oldValue = e.value;
// onlyIfAbsent表示是否仅在oldValue为null的情况下更新键值对的值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //替换旧值时会调用的方法(默认实现为空)
return oldValue;
}
}
++modCount;
//插入成功后,判断实际存在的键值对size > 最大容量threshold
// 若大于,则进行扩容 --> 分析4
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 插入成功时会调用的方法(默认实现为空)
return null;
}
/**
* 分析3: putTreeVal(this,tab,hash,key,value)
* 作用:向红黑树中插入 or 更新数据
* 过程: 遍历红黑树判断该节点
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
给出一个具体的插入流程总结如下图所示:
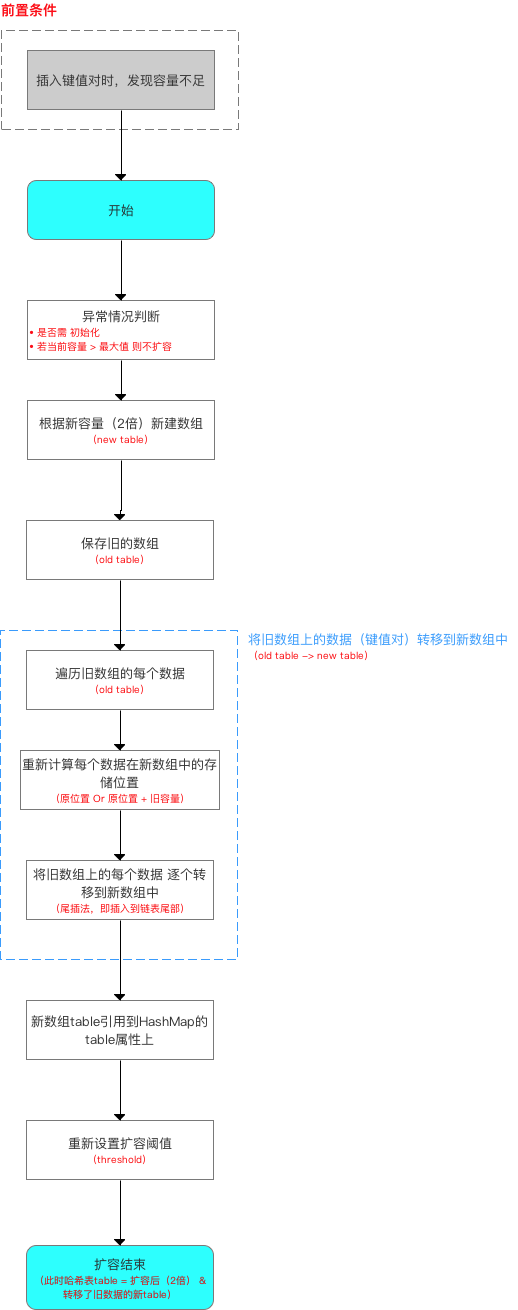
2.2扩容机制(resize()方法)
首先,给出扩容流程如下:
源码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
/**
* 分析4:resize()
* 该函数有2种使用情况:1.初始化哈希表 2.当前数组容量过小,需扩容
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //扩容前的数组(当前数组)
int oldCap = (oldTab == null) ? 0 : oldTab.length; //扩容前的数组的容量 = 长度
int oldThr = threshold; // 扩容前数组的阈值
int newCap, newThr = 0;
//针对情况2
if (oldCap > 0) {
// 若table容量超过容量最大值,则不再扩容,只将阀值设置为最大
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//若无超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//针对情况1:如果当前表是空的,但是有阈值。代表是初始化时指定了容量、阈值的情况
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//如果当前表是空的,而且也没有阈值。代表是初始化时没有任何容量/阈值参数的情况
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//如果新的阈值是0,对应的是 当前表是空的,但是有阈值的情况
float ft = (float)newCap * loadFactor; //根据新表容量 和 加载因子 求出新的阈值
//进行越界修复
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//更新阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//根据新的容量 构建新的哈希桶
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//更新哈希桶引用
table = newTab;
//如果以前的哈希桶中有元素
//下面开始将当前哈希桶中的所有节点转移到新的哈希桶中
if (oldTab != null) {
//遍历老的哈希桶
for (int j = 0; j < oldCap; ++j) {
//取出当前的节点 e
Node<K,V> e;
//如果当前桶中有元素,则将链表赋值给e
if ((e = oldTab[j]) != null) {
//将原哈希桶置空以便GC
oldTab[j] = null;
// 如果当前链表就只有一个元素(没有发生哈希碰撞)
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e; //直接将这个元素放置在新的哈希桶里。注意这里去下标使用哈希值 & 新的桶长度-1. 由于桶的长度是2的n次方,这么做其实是等于 一个模运算。但是效率更高
// 如果发生哈希碰撞,并且节点数超过了8个转换成为了红黑树时,在重新映射,需要对红黑树进行拆分
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 如果发生过哈希碰撞,节点数小于8个。则要根据链表上每个节点的哈希值,依次放入新哈希桶对应下标位置。
else { // preserve order
// 因为扩容是容量翻倍,所以原来链表上的每个节点,现在可能存放在原来的下标,即low位,或者扩容后的下标,即high位。high位= low位 + 原哈希桶容量
Node<K,V> loHead = null, loTail = null; //低位链表的头尾节点
Node<K,V> hiHead = null, hiTail = null; //高位链表的头尾节点
Node<K,V> next; //临时节点,存放e的下一个节点
do {
next = e.next;
// 利用位运算代替常规运算:利用哈希值与旧的容量,可以得到哈希值去模后,是大于等于oldCap还是小于oldCap,等于0代表小于oldCap,应该存放在低位,否则放在高位
if ((e.hash & oldCap) == 0) {
//给头尾节点指针赋值
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//高位也是相同的逻辑
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}//循环直到链表结束
} while ((e = next) != null);
// 将低位链表存放在原index处
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//将高位链表存放在新index处
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
结合上面分析的源码,我们给出扩容流程图如下:

在JDK 1.8中,扩容过程中重新映射需要考虑节点类型。对于树形节点,需先拆分红黑树再映射。对于链表类型节点,则需要先对链表进行分组,然后再映射。需要注意的是,分组后,组内节点相对位置保持不变。我们先来看看链表是如何进行分组映射的。
我们都知道往底层数据结构中插入节点时,一般都是先通过模运算计算桶位置,接着把节点放入桶中即可。事实上我们可以把重新映射看做插入操作。在JDK 1.7中,也确实是这样做的。但在JDK 1.8中,则对这个过程进行了一定的优化,逻辑上要稍微复杂一点。在详细分析之前,我们先来回顾一下求余的过程:

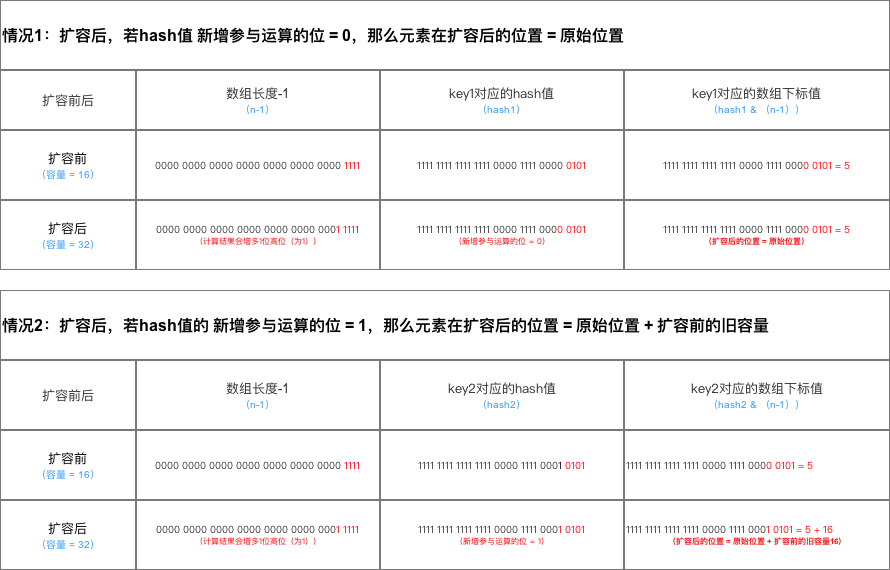
上图中,桶数组大小 = 16,hash1与hash2不相等。但因为只有后4位参与求余,所以结果相等。当桶数组扩容后,n由16变成了32,对上面hash值重新进行映射:

扩容后,参与模运算的位数由4位变成了5位。由于两个hash第5位的值是不一样,所以两个hash算出来的结果也不一样。上面的计算过程并不难理解继续往下分析。
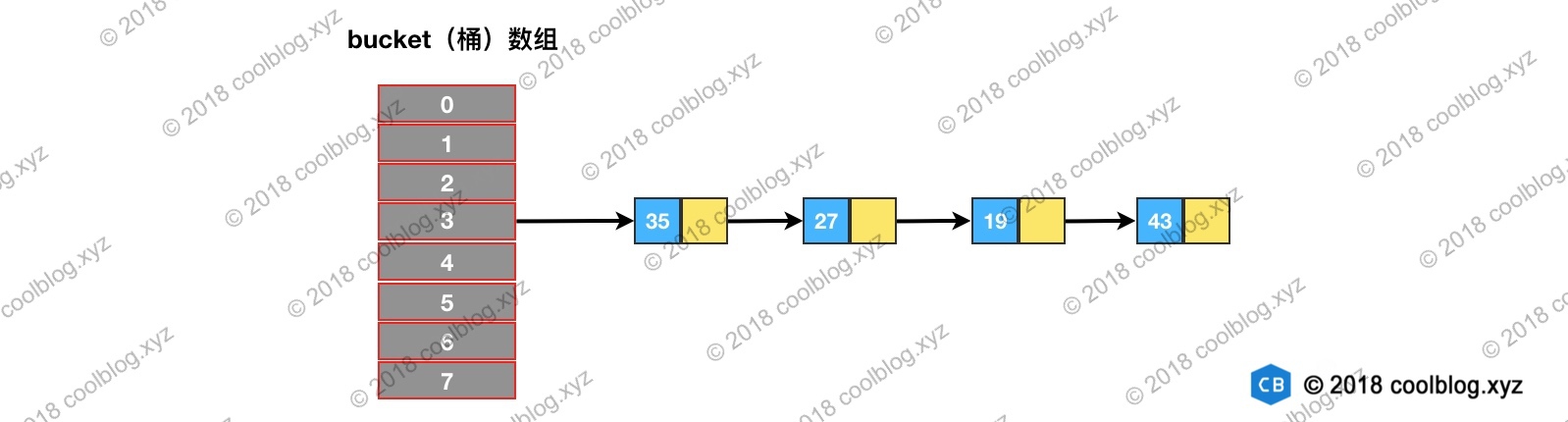
假设我们上图的桶数组进行扩容,扩容后容量n = 16,重新映射过程如下:依次遍历链表,并计算节点hash & oldCap的值。如下图所示:
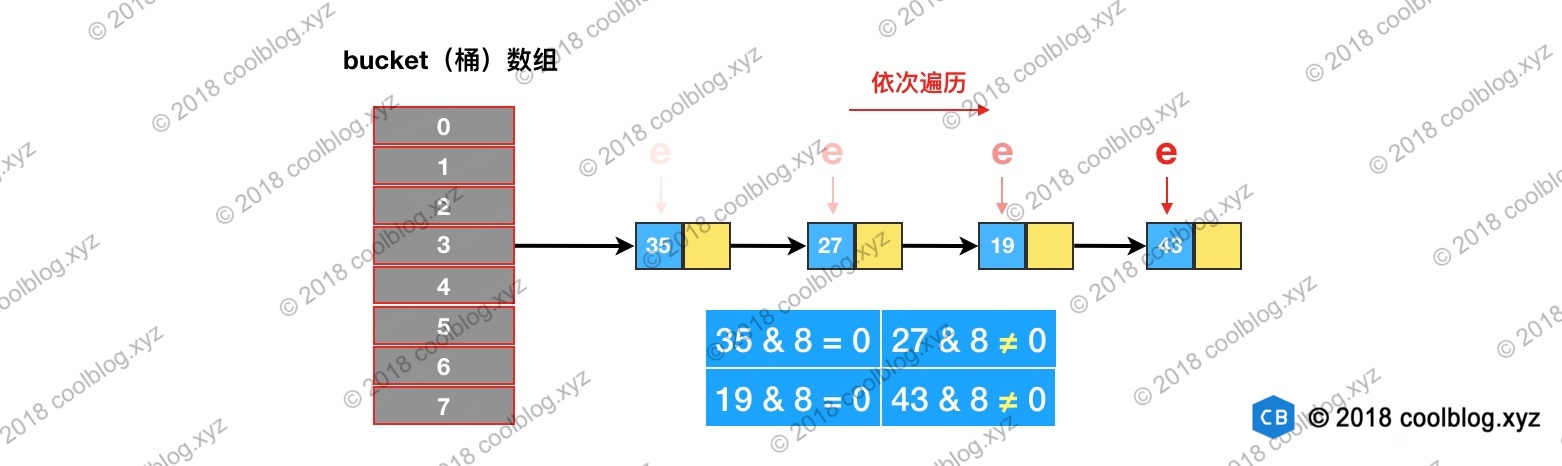
如果值为0,将loHead和loTail的值指向这个节点。如果后面还有节点hash & oldCap为0的话,则将节点链入loHead指向的链表中,并将loTail指向该节点。如果值为非0的话,则让hiHead和hiTail指向该节点。完成遍历后,可能会得到两条链表。此时就完成了链表分组:
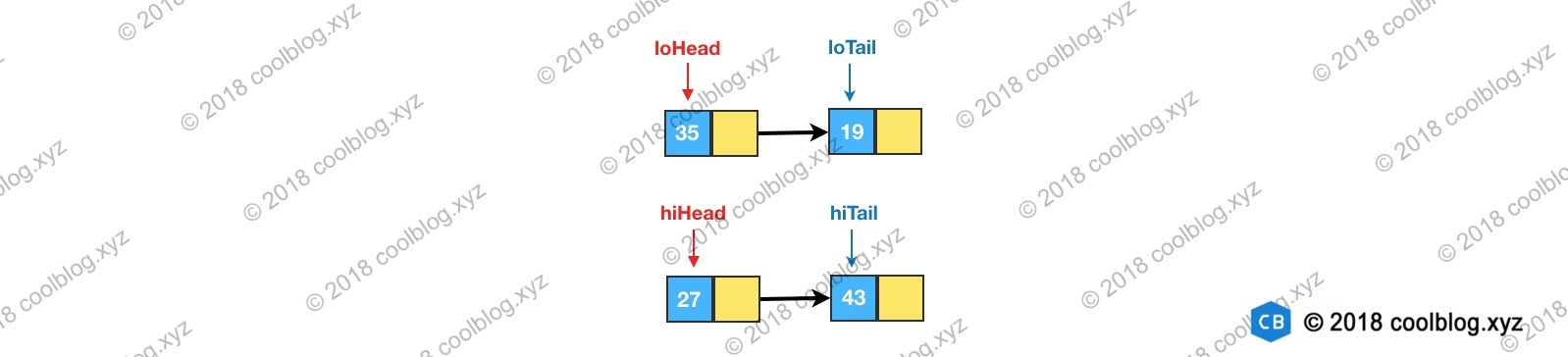
最后,再将这两条链表存放到对应的桶中,完成扩容。如下图所示:
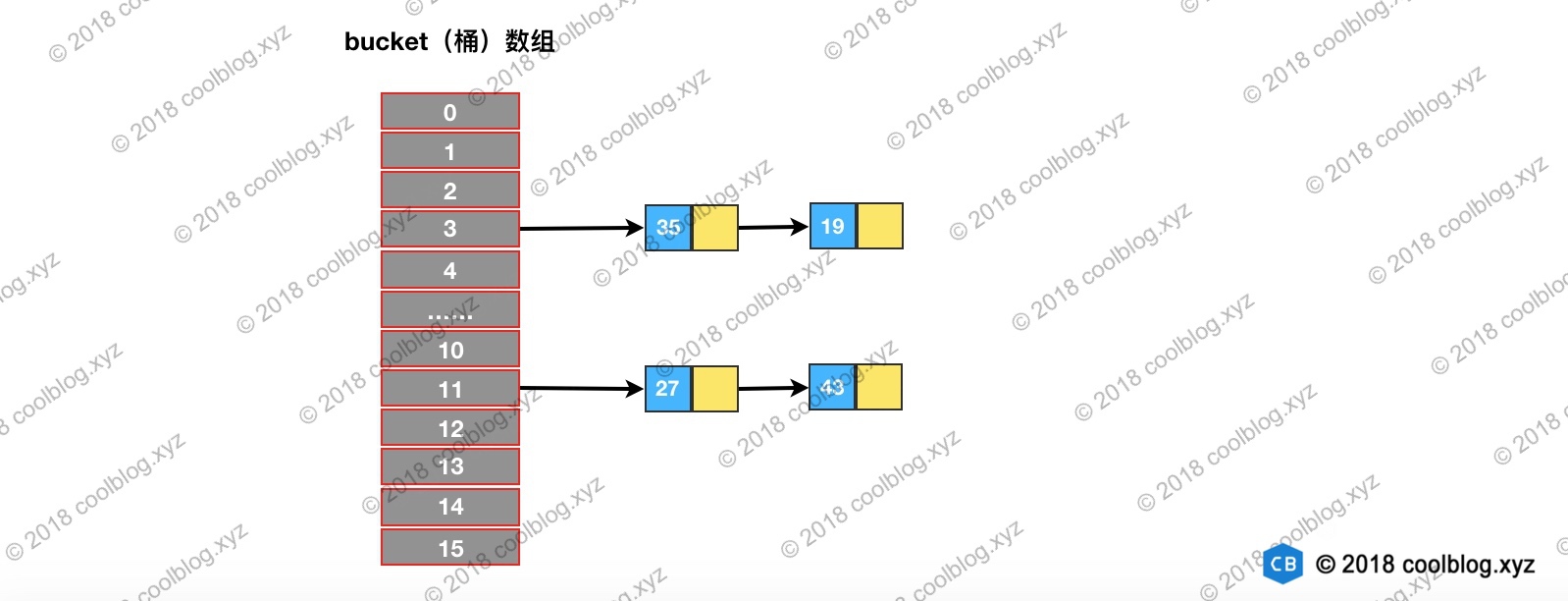
从上图可以发现,重新映射后,两条链表中的节点顺序并未发生变化,还是保持了扩容前的顺序。以上就是 JDK 1.8 中 HashMap 扩容的代码讲解。另外再补充一下,JDK 1.8 版本HashMap 扩容效率要高于之前版本。如果大家看过 JDK 1.7 的源码会发现,JDK 1.7 为了防止因 hash 碰撞引发的拒绝服务攻击,在计算 hash 过程中引入随机种子。以增强 hash 的随机性,使得键值对均匀分布在桶数组中。在扩容过程中,相关方法会根据容量判断是否需要生成新的随机种子,并重新计算所有节点的 hash。而在 JDK 1.8 中,则通过引入红黑树替代了该种方式。从而避免了多次计算 hash 的操作,提高了扩容效率。
为此,我们可以来总结一下JDK 1.87扩容时数据存储位置重新计算的方式:

给出其结论总结示意图如下:
- 链表树化、红黑树链化与拆分
JDK 1.8对HashMap实现进行了改进,最大的改进莫过于引入了红黑树处理频繁的碰撞,代码复杂度也随之上升。比如,以前只需要实现一套针对链表操作的方法即可。而引入红黑树后,则需要另外实现红黑树相关的操作。为此,我们就来分析putVal()方法中所提到的相关红黑树操作。首先,我们先来看看树化的相关代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
// 将普通节点链表转换成树形节点链表
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//当桶数组容量小于MIN_TREEIFY_CAPACITY,优先进行扩容而不是树化
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//hd为头节点,tl为尾结点
TreeNode<K,V> hd = null, tl = null;
do {
//将普通节点替换成树形节点
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null); // 将普通链表转换成树形节点链表
if ((tab[index] = hd) != null)
hd.treeify(tab); // 将树形链表转换成红黑树
}
}
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
/**
* 把红黑树的根节点设为 其所在的数组槽 的第一个元素
* 首先明确:TreeNode既是一个红黑树结构,也是一个双链表结构
* 这个方法里做的事情,就是保证树的根节点一定也要成为链表的首节点
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) { // 根节点不为空 并且 HashMap的元素数组不为空
int index = (n - 1) & root.hash; // 根据根节点的Hash值 和 HashMap的元素数组长度 取得根节点在数组中的位置
TreeNode<K,V> first = (TreeNode<K,V>)tab[index]; // 首先取得该位置上的第一个节点对象
if (root != first) { // 如果该节点对象 与 根节点对象 不同
Node<K,V> rn; // 定义根节点的后一个节点
tab[index] = root; // 把元素数组index位置的元素替换为根节点对象
TreeNode<K,V> rp = root.prev; // 获取根节点对象的前一个节点
if ((rn = root.next) != null) // 如果后节点不为空
((TreeNode<K,V>)rn).prev = rp; // root后节点的前节点 指向到 root的前节点,相当于把root从链表中摘除
if (rp != null) // 如果root的前节点不为空
rp.next = rn; // root前节点的后节点 指向到 root的后节点
if (first != null) // 如果数组该位置上原来的元素不为空
first.prev = root; // 这个原有的元素的 前节点 指向到 root,相当于root目前位于链表的首位
root.next = first; // 原来的第一个节点现在作为root的下一个节点,变成了第二个节点
root.prev = null; // 首节点没有前节点
}
/*
* 这一步是防御性的编程
* 校验TreeNode对象是否满足红黑树和双链表的特性
* 如果这个方法校验不通过:可能是因为用户编程失误,破坏了结构(例如:并发场景下);也可能是TreeNode的实现有问题(这个是理论上的以防万一);
*/
assert checkInvariants(root);
}
}
// For treeifyBin
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
在扩容过程中,树化要满足两个条件:
- 链表长度大于等于TREEIFY_THRESHOLD
- 桶数组容量大于等于MIN_TREEIFY_CAPACITY
对于第二个条件的原因,看到一个比较合理的介绍:当桶数组容量比较小时,键值对节点 hash 的碰撞率可能会比较高,进而导致链表长度较长。这个时候应该优先扩容,而不是立马树化。毕竟高碰撞率是因为桶数组容量较小引起的,这个是主因。容量小时,优先扩容可以避免一些列的不必要的树化过程。同时,桶容量较小时,扩容会比较频繁,扩容时需要拆分红黑树并重新映射。所以在桶容量比较小的情况下,将长链表转成红黑树是一件吃力不讨好的事。
我们继续来看一下treeifyBin方法,该方法主要的作用是将普通链表转换成为由TreeNode节点组成的链表,并在最后调用treeify是将该链表转为红黑树。TreeNode继承自Node类,所以TreeNode仍然包含next引用,原链表的节点顺序最终通过next引用被保存下来。我们假设在树化之前,链表结构如下所示:
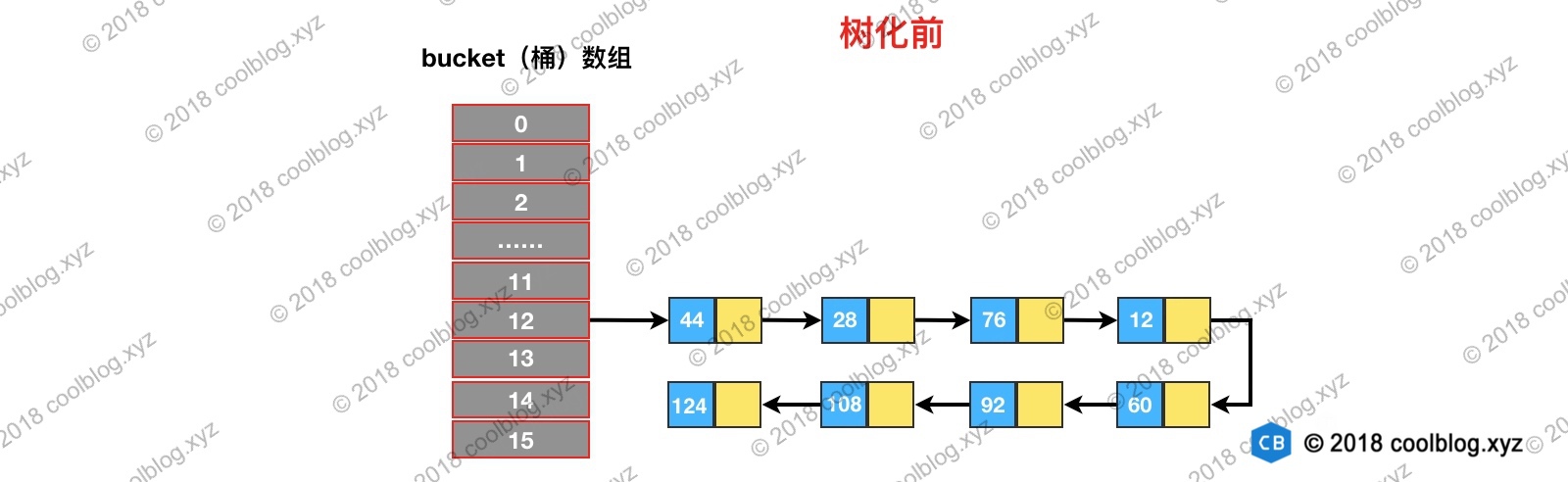
HashMap在设计之初,并没有考虑到以后会引入红黑树进行优化。所以并没有像TreeMap那样,要求键类实现comparable接口或者提供相应的比较器。但由于树化过程中需要比较两个键对象的大小,在键类没有实现comparable接口的情况下,怎么比较键与键之间的大小就成了一个棘手的问题。为了解决这个问题,HashMap是做了三步处理的明确可以比较出两个键的大小:
- 比较键与键之间hash的大小,如果hash相同,继续往下比较
- 检测键类是否实现了Comparable接口,如果实现调用compareTo方法进行比较
- 如果仍未比较出大小,就需要进行仲裁了,仲裁方法为tieBreakOrder方法。
通过上面三次比较,最终就可以比较出孰大孰小。比较出大小后就可以构造红黑树了,最终构造出的红黑树如下所示:
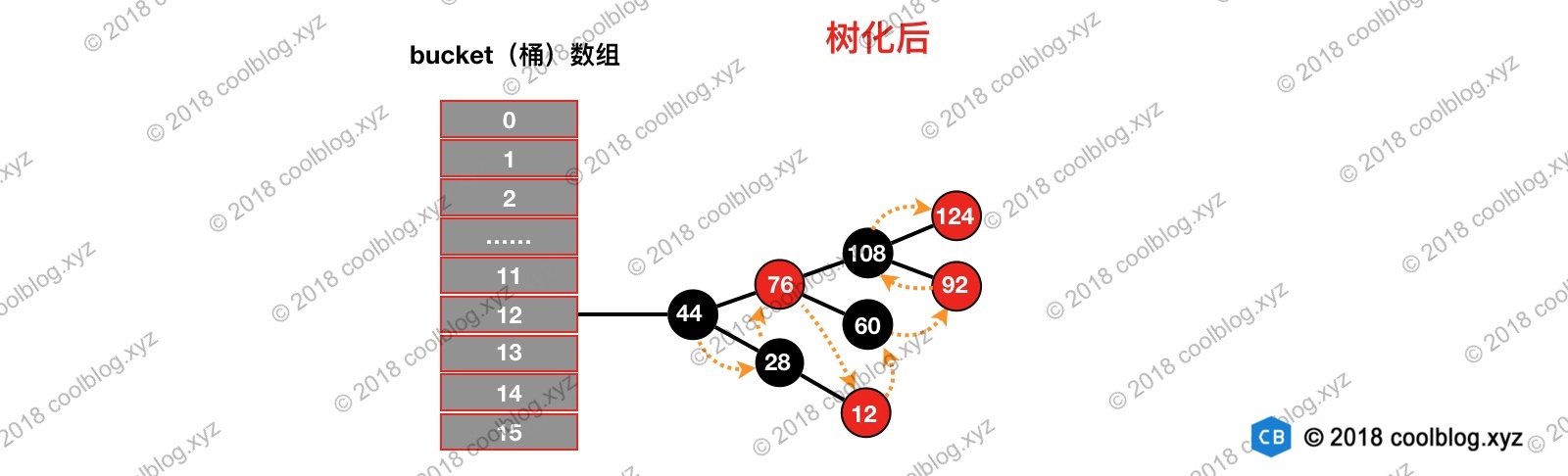
橙色的箭头表示 TreeNode 的 next 引用。由于空间有限,prev 引用未画出。可以看出,链表转成红黑树后,原链表的顺序仍然会被引用仍被保留了(红黑树的根节点会被移动到链表的第一位,并且通过moveRootToFront()还调整了原链表的顺序,具体看上面代码的分析流程),我们仍然可以按遍历链表的方式去遍历上面的红黑树。这样的结构为后面红黑树的切分以及红黑树转成链表做好了铺垫,我们继续往下分析。
红黑树拆分
扩容后,普通节点需要重新映射,红黑树也不例外。按照一般的思路,我们可以先把红黑树转成链表,之后再重新映射链表即可。这种处理方式是大家比较容易想到的,但这样做会损失一定的效率。不同于上面的处理方式,HashMap的实现思路则是很独特。在上节中,在将普通链表转换为红黑树时,HashMap通过两个额外的引用next和prev保留了原链表的节点顺序。这样再对红黑树进行重新映射时,完全可以按照映射链表的方式进行。这样就避免了将红黑树转换成链表后再进行映射,无形中提高了效率。
来看一下红黑树拆分的具体实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
/*
* 红黑树节点仍然保留了 next 引用,故仍可以按链表方式遍历红黑树。
* 下面的循环是对红黑树节点进行分组,与上面类似
*/
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
// 如果 loHead 不为空,且链表长度小于等于 6,则将红黑树转成链表
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
//hiHead == null时,所有节点仍然在原位置,树结构不变,无需重新树化
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
//与上面类似
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
通过源码我们可以看出,重新映射红黑树的逻辑和重新映射链表的基本一致。不同的地方在于,重新映射后,会将红黑树拆分成两条由TreeNode组成的链表。如果链表长度小于UNTREEIFY_THRESHOLD,则将链表转换成普通链表。否则根据条件重新将TreeNode链表树化。举个例子说明一下,假设扩容后,重新映射上图的红黑树,映射结果如下:
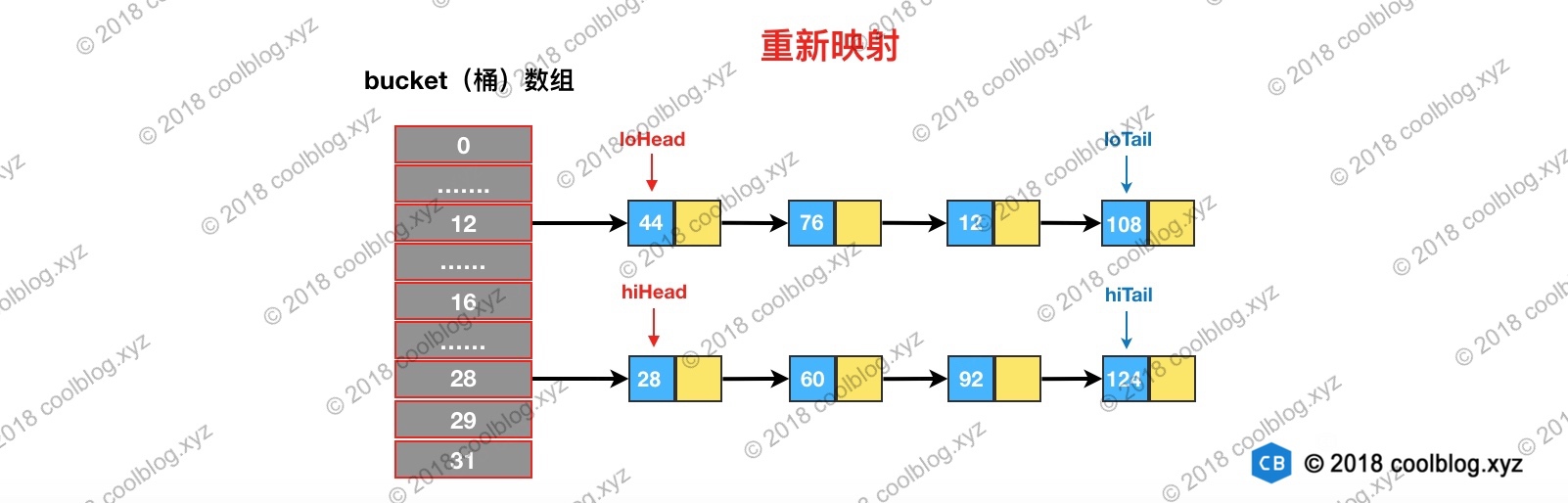
红黑树链化
前面说过,红黑树中仍然保留了原链表节点顺序。有了这个前提,再将红黑树转成链表就简单多了,仅需将 TreeNode 链表转成 Node 类型的链表即可。相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
- 总结
总结一下,添加数据的整体流程:
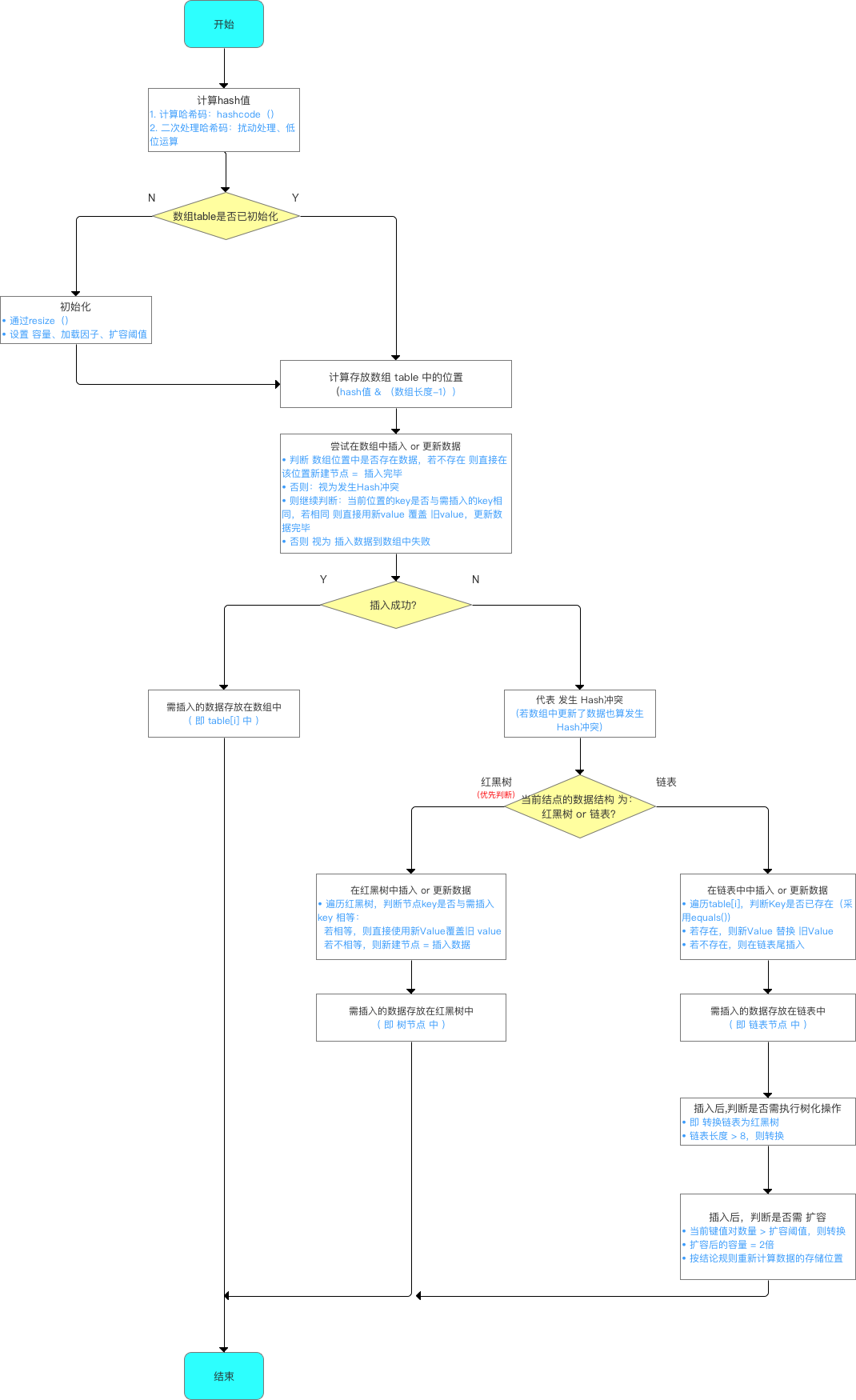
给出添加数据与JDK 1.7的区别内容如下图所示:
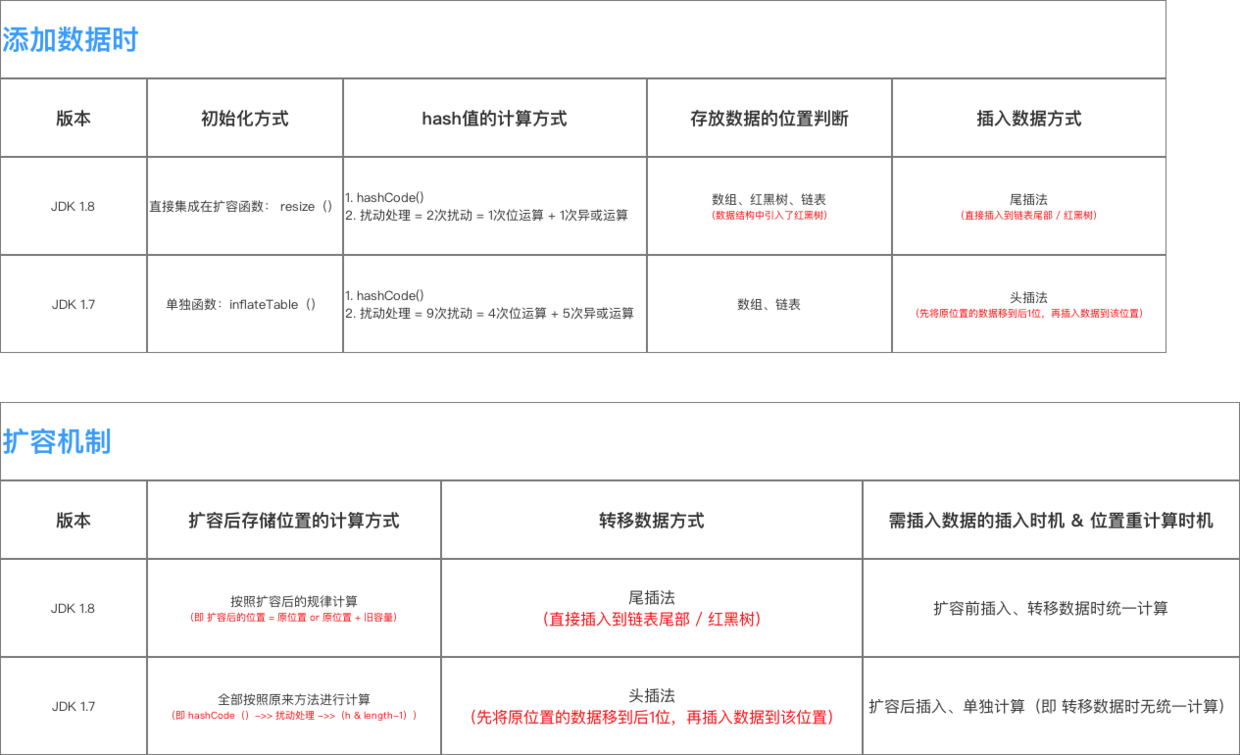
3. get()方法的解析
get()函数的流程如下所示:
- (1)计算需获取数据的hash值(计算过程同put()函数);
- (2)计算存放在数据table中的位置(计算过程同put()函数);
- (3)依次在数组、链表、红黑树中查找(通过equals()判断);
- (4)获取后,判断所获取的数据是否为空(若为空,则返回null).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public V get(Object key) {
Node<K,V> e;
// 1. 计算需获取数据的hash值
// 2. 通过getNode()获取所查询的数据 ->>分析1
// 3. 获取后,判断数据是否为空
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//分析1
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1. 计算存放在数组table中的位置
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// a. 先在数组中找,若存在,则直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// b. 若数组中没有,则到红黑树中寻找
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// c. 若红黑树中也没有,则通过遍历,到链表中寻找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
4.HashMap其他操作的解析
1
2
3
4
5
6
7
8
9
10
11
void clear(); // 清除哈希表中的所有键值对
int size(); // 返回哈希表中所有 键值对的数量 = 数组中的键值对 + 链表中的键值对
boolean isEmpty(); // 判断HashMap是否为空;size == 0时 表示为 空
void putAll(Map<? extends K, ? extends V> m); // 将指定Map中的键值对 复制到 此Map中
V remove(Object key); // 删除该键值对
boolean containsKey(Object key); // 判断是否存在该键的键值对;是 则返回true
boolean containsValue(Object value); // 判断是否存在该值的键值对;是 则返回true
5.源码总结
最后,从三个方面来总结一下整个源码的内容:
- 数据结构与主要参数
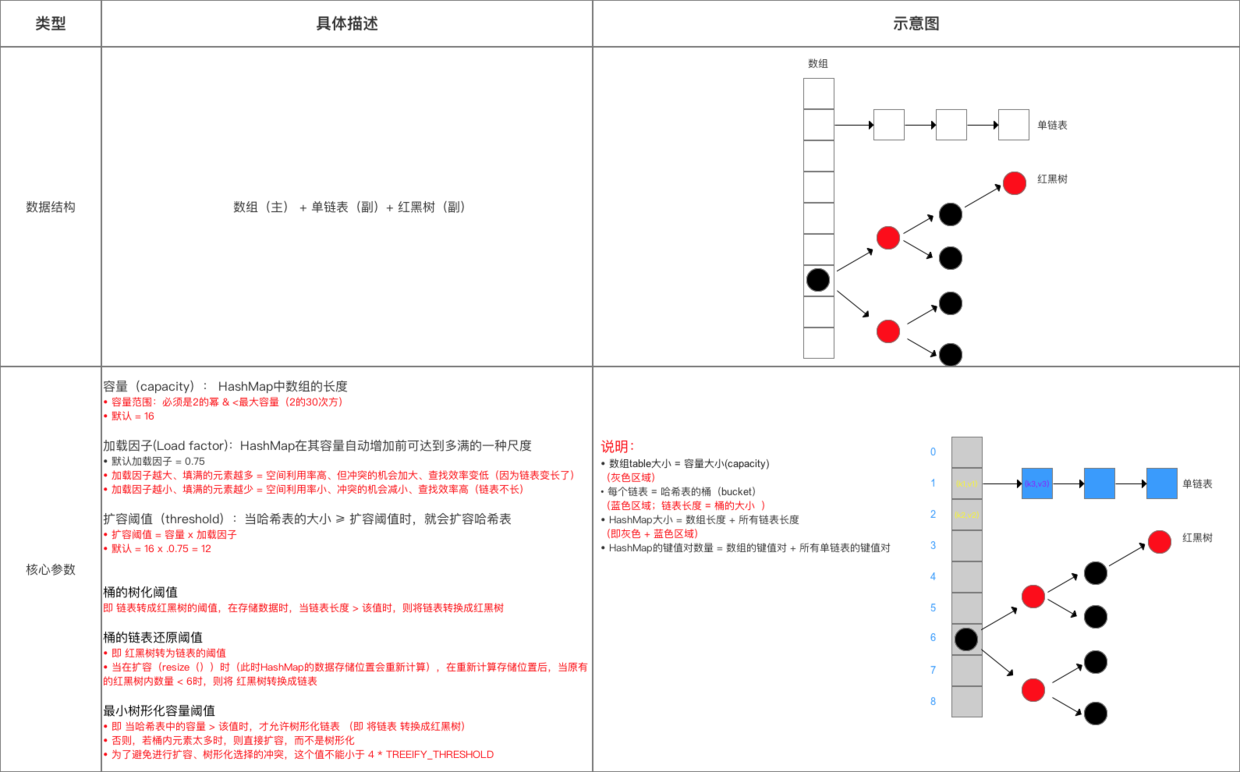
- 添加与查询数据流程
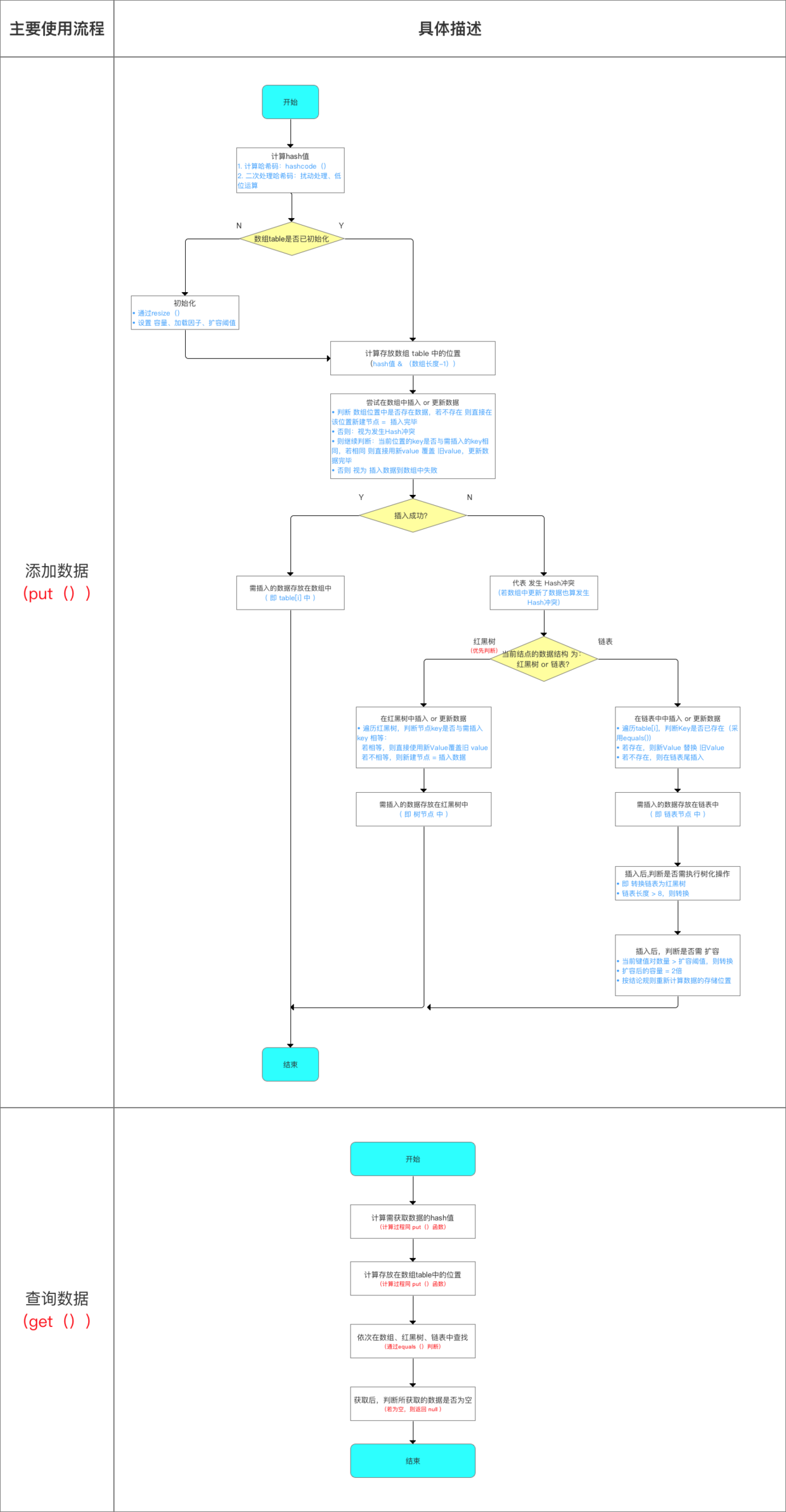
- 扩容机制
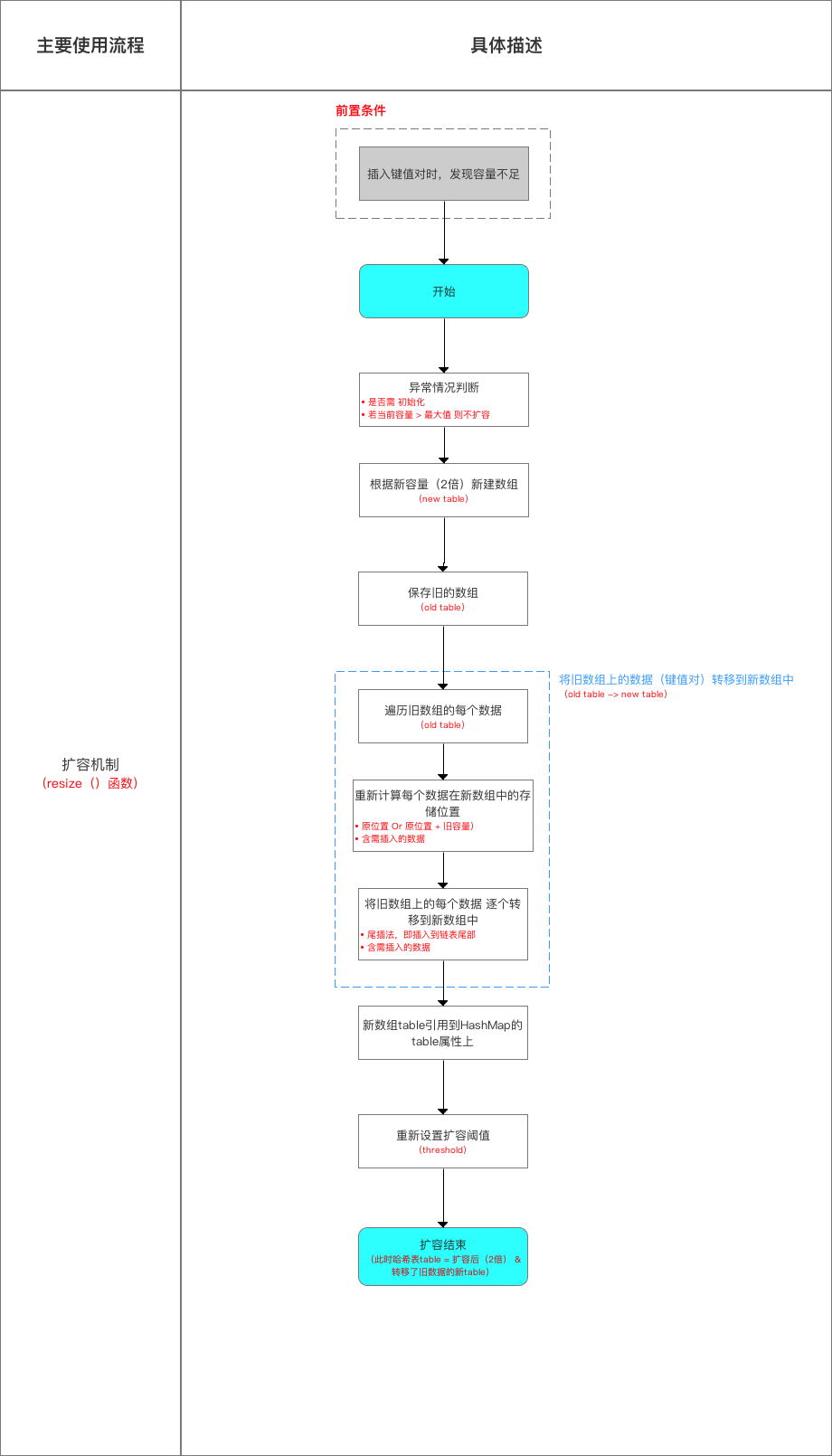
参考文章:
| [面试 | Java8 HashMap原理](https://cloud.tencent.com/developer/article/1376741) |
Java7/8中的HashMap和ConcurrentHashMap源码分析
1.2.4 LinkedHashMap源码分析(JDK 1.7)
LinkedHashMap继承自HashMap,在HashMap的基础上,通过维护一条双向链表,解决了HashMap不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap也对访问顺序提供了相关的支持。在一些场景下,该特性很有用,例如缓存。在实现上,LinkedHashMap很多方法直接继承自HashMap,仅为维护双向链表覆写了部分方法。
简单地来说: LinkedHashMap = 散列表 + 循环双向链表
LinkedHashMap是HashMap的子类,在拥有HashMap功能之外可以保存元素插入顺序,使得元素遍历顺序与元素插入顺序相同。同时LinkedHashMap还可以根据元素访问的时间先后顺序来遍历元素,Lru(Least recently used)算法中就是应用了LinkdHashMap这一性质。在介绍源码之前,我们先来说一下它的特点:
- 能够保证插入元素的顺序。深入一点讲,有两种迭代元素的方式,一种是按照插入元素时的顺序迭代,比如,插入A,B,C,那么迭代的时候也是A,B,C。另一种是按照访问顺序,比如,在迭代前,访问了B,那么迭代的顺序就是A,C,B,比如在迭代前,访问了B,接着又访问了A,那么迭代顺序为C,B,A,比如,在迭代前访问了B,接着又访问了B,然后在访问了A,迭代顺序还是C,B,A。要说明的意思就是不是近期访问的次数最多,就放最后面迭代,而是看迭代前被访问的时间长短决定。
- 内部存储的元素的模型。entry是下面这样的,相比较HashMap,它多了两个属性,一个before,一个after。next和after有时候会指向同一个entry,有时候next指向null,而after指向entry。这个具体后面分析。

- linkedHashMap和HashMap在存储操作上是一样的,但是LinkedHashMap多的东西是会记住在此之前插入的元素,这些元素不一定是在一个桶中。给出LinkedHashMap的结构图如下所示(多了header指向双向链表的头部,这是一个哑元):

1.类声明
1
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
HashMap继承自HashMap,实现了Map接口,Map接口定义了所有Map子类必须实现的方法。LinkedHashMap主要对Entry的结构进行了扩展,在继承父类Entry的基础上,有添加的两个属性Entry<K,V> before, after。并且添加了addBefore()方法。我们来分析一下其实现的Entry类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
private transient Entry<K,V> header;
private final boolean accessOrder;
//LinkedHashMap的entry继承自HashMap的Entry。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
//通过上面这句源码的解释,我们可以知道这两个字段,是用来给迭代时使用的,相当于一个双向链表,实际上用的时候,操作LinkedHashMap的entry和操作HashMap的Entry是一样的,只操作相同的四个属性,这两个字段是由linkedHashMap中一些方法所操作。所以LinkedHashMap的很多方法度是直接继承自HashMap。
//before:指向前一个entry元素。after:指向后一个entry元素
Entry<K,V> before, after;
//使用的是HashMap的Entry构造
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//下面是维护这个双向循环链表的一些操作。在HashMap中没有这些操作,因为HashMap不需要维护,
/**
* Removes this entry from the linked list.
*/
//我们知道在双向循环链表时移除一个元素需要进行哪些操作把,比如有A,B,C,将B移除,那么A.next要指向c,c.before要指向A。下面就是进行这样的操作,但是会有点绕,他省略了一些东西。
//有的人会问,要是删除的是最后一个元素呢,那这个方法还适用吗?有这个疑问的人应该注意一下这个是双向循环链表,双向,删除哪个度适用。
private void remove() {
//this.before.after = this.after;
//this.after.before = this.before; 这样看可能会更好理解,this指的就是要删除的哪个元素。
before.after = after;
after.before = before;
}
/**
* Inserts this entry before the specified existing entry in the list.
*/
//插入一个元素之后做的一些操作,就是将第一个元素,和最后一个元素的一些指向改变。传进来的existingEntry就是header。
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
//这个方法就是我们一开始说的,accessOrder为true时,就是使用的访问顺序,访问次数最少到访问次数最多,此时要做特殊处理。处理机制就是访问了一次,就将自己往后移一位,这里就是先将自己删除了,然后在把自己添加,
//这样,近期访问的少的就在链表的开始,最近访问的元素就会在链表的末尾。如果为false。那么默认就是插入顺序,直接通过链表的特点就能依次找到插入元素,不用做特殊处理。
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
2.构造函数
构造函数除了正常调用父类HashMap的构造函数之外,还初始化了accessOrder为false.accessOrder为false时,表明遍历元素是按照插入顺序来访问,即遍历输出顺序和当初元素插入顺序相同;accessOrder为true时,表明遍历元素顺序是根据访问元素时间先后顺序来遍历元素,即最近访问的元素最后输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
//使用父类中的构造,初始化容量和加载因子,该初始化容量是指数组大小。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
//真正有点特殊的就是这个,多了一个参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个,
//true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素
//如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
可以看到linkedHashMap所有的构造方法里都调用了父类相关的构造方法,在父类构造中有调用了init方法,而linkedHashMap又覆盖了init方法,因此初始化先执行父类相关的操作,再执行自己init方法:
1
2
3
4
5
6
7
//linkedHashMap中的init()方法,就使用header,hash值为-1,其他参数为null,也就是说这个header不放在数组中,就是用来指示开始元素和标志结束元素的
@Override
void init() {
header = new Entry<>(-1, null, null, null);
//一开始是自己指向自己,没有任何元素
header.before = header.after = header;
}
在HashMap构造函数有个init函数没有实现,在LinkedHashMap中实现了。可以看出这个函数new了一个Entry类型的header节点,Entry继承了HashMapEntry,增加了before和after指针,进行了初始化。
3.LinkedHashMap的put()操作与扩容
put()操作
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意:这里的插入有两重含义:
- 从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。
- 从header的角度看,新的entry需要插入到双向链表的尾部。

因为在LinkedHashMap中没有实现put函数,而是调用了HashMap的put函数,为此,我们先来回顾一下HashMap的put()方法如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//HashMap put()方法实现
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//空实现,交给 LinkedHashMap 自己实现
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// LinkedHashMap 对其重写
addEntry(hash, key, value, i);
return null;
}
其中recordAccess是HashMapEntry的成员函数,在HashMap中是个空函数,具体实现在LinkedHashMap中。可以猜想这个函数与LinkedHashMap的顺序存储有关。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//首先判断是否为当前是否为访问顺序模式,如果是则需要将当前这个 Entry 移动到链表的末尾
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
// 这里其实是删除双链表单节点的操作,
private void remove() {
//当前节点的前一个节点的after指针指向当前节点的后一个节点。
before.after = after;
// before指针指向当前节点的前一个节点。
after.before = before;
}
// 将当前节点插入到环形链表的头节点的前一个节点,其实也就是双链表的尾部
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
重写了addEntry()和createEntry()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void addEntry(int hash, K key, V value, int bucketIndex) {
// 调用父类的addEntry
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//默认是返回false的,也就是说如果想要根据元素访问的时间先后顺序来遍历元素,还需要重写该方法
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
在自己的addEntry方法里面又调用了父类的方法,父类的方法如下:
1
2
3
4
5
6
7
8
9
10
void addEntry(int hash, K key, V value, int bucketIndex) {
//看是否需要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 又调用createEntry
createEntry(hash, key, value, bucketIndex);
}
addEntry方法里又调用createEntry,同样linkedHashMap覆盖了父类的createEntry,调用本地的:
1
2
3
4
5
6
7
8
9
10
//重写的createEntry,这里要注意的是,新元素放桶中,是放第一位,而不是往后追加,所以下面方法中前面三行应该知道了
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//这个方法的作用就是将e放在双向循环链表的末尾,需要将一些指向进行修改的操作。。
e.addBefore(header);
size++;
}
把Entry利用头插法添加到数组里面之后,又调用了entry对象的addBefore方法,该方法主要是将当前Entry节点的after指针指向header,before指针指向上一次put的entry,header的before指针指向当前Entry节点,这样在下一次put新的Entry时总能通过header的before指针找到上一次put的Entry,从而维持Entry节点之间的先后顺序。
1
2
3
4
5
6
7
// Entry的对象方法
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
扩容操作
LinkedHashMap与HashMap的扩容也是有一点不同的,它重写了resize()方法中transfer函数。HashMap是通过遍历每个链表将旧元素拷贝到新的数组中,而LinkedListMap由于有双向链表来维护所有元素,因此直接遍历双向链表来拷贝旧元素。从遍历的效率来讲,遍历双链表的效率要高于遍历table,因为遍历双向链表是N次(N为元素个数);而遍历table是N+table的空余个数(N为元素个数)。
1
2
3
4
5
6
7
8
9
10
11
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
4. 迭代器的实现
来分析一下迭代器的使用,其实现了对双向循环链表的遍历操作。但是这个迭代器是abstract的,不能直接被对象所用,但是能够间接使用,就是通过keySet().interator()来访问。(hashMap中的keySet() -> LinkedHashMap.newKeyIterator() -> LinkedHashMap.KeyIterator())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
private abstract class LinkedHashIterator<T> implements Iterator<T> {
//先拿到header的after指向的元素,也就是第一个元素。
Entry<K,V> nextEntry = header.after;
//记录前一个元素是谁,因为刚到第一个元素,第一个元素之前的元素理论上就是null。实际上是指向最后一个元素的。知道就行。
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
//判断有没有到循环链表的末尾,就看元素的下一个是不是header。
public boolean hasNext() {
return nextEntry != header;
}
//移除操作,也就一些指向问题
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
//下一个元素。一些指向问题,度是双向循环链表中的操作。
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
5.get()方法与remove()方法
LinkedHashMap也重写了get()方法,get()方法解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
//多了一个判断是否是按照访问顺序排序,是则将当前的 Entry 移动到链表头部。
e.recordAccess(this);
return e.value;
}
// 这个方法在上面已经分析过了,如果accessOrder为true,那么就会用访问顺序。if条件下的语句会执行,作用就是将最近访问的元素放链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
remove()方法的作用是删除key值对应的entry,调用了hashMap的remove()方法。其主要实体方法就是removeEntryForKey(),该方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似,LinkedListMap重写了其中recordRemoval()方法,实现了修改链表中前面以及后面元素的相应引用。注意,这里的删除也包含着两重含义:
- 从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。
- 从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// hashMao removeEntryForKey()方法
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
// LinkedHashMap重写了该方法
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
// LinkedListMap的Entry类
void recordRemoval(HashMap<K,V> m) {
remove();
}
private void remove() {
before.after = after;
after.before = before;
}
clear()方法就很简单了:
1
2
3
4
5
//只需要把指针都指向自己即可,原本那些 Entry 没有引用之后就会被 JVM 自动回收。
public void clear() {
super.clear();
header.before = header.after = header;
}
6.LinkedHashMap经典用法
LinkedHashMap除了可以保证迭代顺序外,还有一个非常有用的用法:可以轻松实现一个采用了FIFO替换策略的缓存。具体说来,LinkedHashMap有一个子类方法protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉Map是否要删除“最老”的Entry,所谓最老就是当前Map中最早插入的Entry,如果该方法返回true,最老的那个元素就会被删除。在每次插入新元素的之后LinkedHashMap会自动询问removeEldestEntry()是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让removeEldestEntry()返回true,就能够实现一个固定大小的FIFO策略的缓存。示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
/** 一个固定大小的FIFO替换策略的缓存 */
public class LRUCache<K, V> extends LinkedHashMap<K, V>{
private final int maxCapacity;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final Lock lock = new ReentrantLock();
public LRUCache(int maxCapacity){
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
@Override
public boolean containsKey(Object key) {
try{
lock.lock();
return super.containsKey(key);
}finally {
lock.unlock();
}
}
@Override
public V get(Object key) {
try {
lock.lock();
return super.get(key);
}finally {
lock.unlock();
}
}
@Override
public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
}finally {
lock.unlock();
}
}
@Override
public int size() {
try {
lock.lock();
return super.size();
}finally {
lock.unlock();
}
}
@Override
public void clear() {
try {
lock.lock();
super.clear();
}finally {
lock.unlock();
}
}
public List<Map.Entry<K, V>> getAll(){
try {
lock.lock();
return new ArrayList<Map.Entry<K, V>>(super.entrySet());
}finally {
lock.unlock();
}
}
}
1.2.5 LinkedHashMap源码分析(JDK 1.8)
1.概要
概括地说,LinkedHashMap是一个关联数组、哈希表,它是线程不安全的,允许key为null,value为null。它继承自HashMap,实现了Map<K,V>接口。其内部还维护了一个双向链表,在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。
因继承自HashMap,所以HashMap前文分析的特点,除了输出无序,其他LinkedHashMap都有,比如扩容的策略,哈希桶长度一定是2的N次方等等。LinkedHashMap在实现时,就是重写override了几个方法。以满足其输出序列有序的需求。JDK 1.7没有给出LinkedHashMap的使用案例,为此,本文给出一段示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Map<String, String> map = new LinkedHashMap<>();
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d");
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("以下是accessOrder=true的情况:");
map = new LinkedHashMap<String, String>(10, 0.75f, true);
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d");
map.get("2");//2移动到了内部的链表末尾
map.get("4");//4调整至末尾
map.put("3", "e");//3调整至末尾
map.put(null, null);//插入两个新的节点 null
map.put("5", null);//5
iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
1=a
2=b
3=c
4=d
以下是accessOrder=true的情况:
1=a
2=b
4=d
3=e
null=null
5=null
2. 原理
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构。该结构由数组和链表或红黑树组成,结构示意图大致如下:

只不过LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。其结构可能如下图:

上图中,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
3.源码分析
3.1 Entry节点与继承体系
LinkedHashMap的节点Entry<K,V>继承自HashMap.Node<K,V>,在其基础上扩展了一下。改成了一个双向链表。详细的应该是这样:entry <—- before + entry(hash + key + value + next) + after —–> entry。可能next和after全都指向一个entry,也有可能next —-> null, 而after ——> entry。
1
2
3
4
5
6
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
另外,类里有两个成员变量head tail,分别指向内部双向链表的表头、表尾。
1
2
3
4
5
//双向链表的头结点
transient LinkedHashMap.Entry<K,V> head;
//双向链表的尾节点
transient LinkedHashMap.Entry<K,V> tail;
在对核心内容展开分析之前,我们来分析一下键值对节点的继承体系,下图给出了继承体系结构图:

LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。但是我们在看上图的继承体系的时候,我们会存在这样一个困惑:为什么HashMap的内部类TreeNode不继承它的一个内部类Node,却继承了Node的子类LinkedHashMap内部类Entry,而且在相关方法中也没有到Entry的before与after指针,这样做不是浪费空间吗?
这里这么做确实会浪费空间,但与 TreeNode 通过继承获取的组成链表的能力相比,这点浪费是值得的。其实,这当然是与LinkedHashMap有关。若是TreeNode直接继承自Node,那么对于LinkedHashMap#Entry就要继承自TreeNode,那么对于LinkedHashMap来说它的每个节点都将含有left,right,parent,prev四个指针,这是没必要的,浪费空间。所以采用 TreeNode 继承LinkedHashMap.Entry的方式,当然对于HashMap,它没有任何关于before/after的操作,对于它来说这是种浪费,但相比较而言采用这种方式更好。而且,对于HashMap来说若 key 的hashCode方法实现的够好的化,指的是分布均匀,那么树将很少出现。
3.2 构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
//默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。
//为true时,可以在这基础之上构建一个LruCach
final boolean accessOrder;
//指定初始化时的容量,和扩容的加载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//指定初始化时的容量,
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
//指定初始化时的容量,和扩容的加载因子,以及迭代输出节点的顺序
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
可以看到前四个构造器accessOrder都为false,也就是保持插入顺序;最后一个提供了设置accessOrder值,用于控制迭代时节点的顺序。LinkedHashMap的构造函数就是调用HashMap的,再加上accessOrder的设置。head 是最早插入的或是最久未被操作的节点,tail 与其相反。
3.3 链表的建立过程
链表的建立过程是在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。
Map类型的集合类是通过put(K,V)方法插入键值对,LinkedHashMap本身并没有覆写父类的put方法,而是直接使用了父类的实现。但在HashMap中,put方法插入的是HashMap的内部类Node类型的节点,该类型的节点并不具备与 LinkedHashMap 内部类 Entry 及其子类型节点组成链表的能力。那么,LinkedHashMap 是怎样建立链表的呢?在展开说明之前,我们先看一下 LinkedHashMap 插入操作相关的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
// HashMap 中实现
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// HashMap中实现
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 遍历链表,并统计链表长度
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 回调方法,后续说明
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict); //回调方法,后续说明
return null;
}
// HashMap 中实现
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
// LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
// LinkedHashMap 中实现
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
上面就是 LinkedHashMap 插入相关的源码,这里省略了部分非关键的代码。根据上面的代码,可以知道 LinkedHashMap 插入操作的调用过程。如下:

通过newNode 方法红色背景标注了出来,这一步比较关键。LinkedHashMap 覆写了该方法。在这个方法中,LinkedHashMap 创建了 Entry,并通过 linkNodeLast 方法将 Entry 接在双向链表的尾部,实现了双向链表的建立。双向链表建立之后,我们就可以按照插入顺序去遍历 LinkedHashMap。
以上就是 LinkedHashMap 维护插入顺序的相关分析。本节的最后,再额外补充一些东西。大家如果仔细看上面的代码的话,会发现有两个以after开头方法,在上文中没有被提及。在 JDK 1.8 HashMap 的源码中,相关的方法有3个:
1
2
3
4
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
根据这三个方法的注释可以看出,这些方法的用途是在增删查等操作后,通过回调的方式,让 LinkedHashMap 有机会做一些后置操作。先来分析一下afterNodeInsertion(evict)方法,后面再具体的进行分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
//回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//LinkedHashMap 默认返回false 则不删除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
void afterNodeInsertion(boolean evict)以及boolean removeEldestEntry(Map.Entry<K,V> eldest)是构建LruCache需要的回调,在LinkedHashMap里可以忽略它们。
3.4 链表节点的删除过程
与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现。在删除节点时,父类的删除逻辑并不会修复 LinkedHashMap 所维护的双向链表,这不是它的职责。那么删除及节点后,被删除的节点该如何从双链表中移除呢?当然,办法还算是有的。上一节最后提到 HashMap 中三个回调方法运行 LinkedHashMap 对一些操作做出响应。所以,在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作。相关源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
//HashMap中实现
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
//HashMap中实现
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
}
// LinkedHashMap中覆写
//在删除节点e时,同步将e从双向链表上删除
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将p节点的前驱后继节点引用置空
p.before = p.after = null;
// b为null,表明p是头节点
if (b == null)
head = a;
else //否则将前置节点b的后置节点指向a
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点。
举个例子说明一下,假如我们要删除下图键值为 3 的节点:

根据hash定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历,找到要删除的节点后,先从单链表中移除该节点。如下:

然后再双向链表中移除该节点:

3.5 访问顺序的维护过程
默认情况下,LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。相应的源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
// LinkedHashMap 中覆写
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;//原尾节点
//如果accessOrder 是true ,且原尾节点不等于e
if (accessOrder && (last = tail) != e) {
//节点e强转成双向链表节点p
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p现在是尾节点, 后置节点一定是null
p.after = null;
//如果p的前置节点是null,则p以前是头结点,所以更新现在的头结点是p的后置节点a
if (b == null)
head = a;
else//否则更新p的前直接点b的后置节点为 a
b.after = a;
//如果p的后置节点不是null,则更新后置节点a的前置节点为b
if (a != null)
a.before = b;
else//如果原本p的后置节点是null,则p就是尾节点。 此时 更新last的引用为 p的前置节点b
last = b;
if (last == null) //原本尾节点是null 则,链表中就一个节点
head = p;
else {//否则 更新 当前节点p的前置节点为 原尾节点last, last的后置节点是p
p.before = last;
last.after = p;
}
//尾节点的引用赋值成p
tail = p;
//修改modCount。
++modCount;
}
}
上面就是访问顺序的实现代码,并不复杂.值得注意的是,afterNodeAccess()函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。下面举例演示一下,帮助大家理解。假设我们访问下图键值为3的节点,访问前结构为:

访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下:

此外,LinkedHashMap重写了containsValue()方法,相比HashMap的实现,它更高效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// LinkedHashMap 中覆写
public boolean containsValue(Object value) {
//遍历一遍链表,去比较有没有value相等的节点,并返回
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
// HashMap实现,两个for循环
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
3.6 遍历
重写了entrySet()如下:
1
2
3
4
5
6
7
8
9
10
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
//返回LinkedEntrySet
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
}
最终的EntryIterator:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
abstract class LinkedHashIterator {
//下一个节点
LinkedHashMap.Entry<K,V> next;
//当前节点
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
//初始化时,next 为 LinkedHashMap内部维护的双向链表的扁头
next = head;
//记录当前modCount,以满足fail-fast
expectedModCount = modCount;
//当前节点为null
current = null;
}
//判断是否还有next
public final boolean hasNext() {
//就是判断next是否为null,默认next是head 表头
return next != null;
}
//nextNode() 就是迭代器里的next()方法 。
//该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。
final LinkedHashMap.Entry<K,V> nextNode() {
//记录要返回的e。
LinkedHashMap.Entry<K,V> e = next;
//判断fail-fast
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//如果要返回的节点是null,异常
if (e == null)
throw new NoSuchElementException();
//更新当前节点为e
current = e;
//更新下一个节点是e的后置节点
next = e.after;
//返回e
return e;
}
//删除方法 最终还是调用了HashMap的removeNode方法
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
值得注意的就是:nextNode() 就是迭代器里的next()方法 。该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。而双链表节点的顺序在LinkedHashMap的增、删、改、查时都会更新。以满足按照插入顺序输出,还是访问顺序输出。
3.7 基于 LinkedHashMap 实现缓存
这里通过继承 LinkedHashMap 实现了一个简单的 LRU 策略的缓存。在写代码之前,先介绍一下前置知识。
1
2
3
4
5
6
7
8
9
10
11
12
13
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
上面的源码的核心逻辑在一般情况下都不会被执行,所以之前并没有进行具体分析。上面的代码做的事情比较简单,就是通过一些条件,判断是否移除最近最少被访问的节点。看到这里,大家应该知道上面两个方法的用途了。当我们基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如我们可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。本节所实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class SimpleCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_NODE_NUM = 100;
private int limit;
public SimpleCache() {
this(MAX_NODE_NUM);
}
public SimpleCache(int limit) {
super(limit, 0.75f, true);
this.limit = limit;
}
public V save(K key, V val) {
return put(key, val);
}
public V getOne(K key) {
return get(key);
}
public boolean exists(K key) {
return containsKey(key);
}
/**
* 判断节点数是否超限
* @param eldest
* @return 超限返回 true,否则返回 false
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > limit;
}
测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class SimpleCacheTest {
@Test
public void test() throws Exception {
SimpleCache<Integer, Integer> cache = new SimpleCache<>(3);
for (int i = 0; i < 10; i++) {
cache.save(i, i * i);
}
System.out.println("插入10个键值对后,缓存内容:");
System.out.println(cache + "\n");
System.out.println("访问键值为7的节点后,缓存内容:");
cache.getOne(7);
System.out.println(cache + "\n");
System.out.println("插入键值为1的键值对后,缓存内容:");
cache.save(1, 1);
System.out.println(cache);
}
}
测试结果:

在测试代码中,设定缓存大小为3。在向缓存中插入10个键值对后,只有最后3个被保存下来了,其他的都被移除了。然后通过访问键值为7的节点,使得该节点被移到双向链表的最后位置。当我们再次插入一个键值对时,键值为7的节点就不会被移除。
4.总结
LinkedHashMap相对于HashMap的源码比,是很简单的。因为大树底下好乘凉。它继承了HashMap,仅重写了几个方法,以改变它迭代遍历时的顺序。这也是其与HashMap相比最大的不同。 在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序
accessOrder,默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。为true时,可以在这基础之上构建一个LruCache.LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法.在每次构建新节点时,将新节点链接在内部双向链表的尾部.accessOrder=true的模式下,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。值得注意的是,afterNodeAccess()函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。nextNode()就是迭代器里的next()方法.该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。而双链表节点的顺序在LinkedHashMap的增、删、改、查时都会更新。以满足按照插入顺序输出,还是访问顺序输出.- 它与HashMap比,还有一个小小的优化,重写了containsValue()方法,直接遍历内部链表去比对value值是否相等。
参考文章
1.2.6 ConcurrentHashMap源码分析(JDK 1.7)
ConcurrentHashMap相当于多线程版本的HashMap,不会有线程安全问题,在多线程环境下使用HashMap可能会产生死循环等问题(jdk 1.7头插法带来的问题)。我们知道除了HashMap还有线程安全的HashTable,HashTable的实现原理与HashMap一致,只是HashTable所有的方法都是用synchronized来修饰确保线程安全性,这在多线程竞争激烈的环境下效率是很低的。而ConcurrentHashMap通过分段锁,把整个哈希表ConcurrentHashMap分成了多个片段(Segment),来确保线程安全。下面是JDK对ConcurrentHashMap的介绍:
A hash table supporting full concurrency of retrievals and high expected concurrency for updates. This class obeys the same functional specification as Hashtable, and includes versions of methods corresponding to each method of Hashtable. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access. This class is fully interoperable with Hashtable in programs that rely on its thread safety but not on its synchronization details.
大意是ConcurrentHashMap支持并发的读写,支持HashTable的所有方法,实现并发读写不会锁定整个ConcurrentHashMap。
1. ConcurrentHashMap数据结构
我们来回忆一下之前讲述的HashMap的数据结构(JDK 7版本),核心就是一个键值对Entry数组,键值对通过键的hash值映射到数组上:

大方向上,HashMap里面是一个数组,然后每个数组中的每个元素是一个单向链表。而ConcurrentHashMap与之类似,它是拥有一个Segment数组,Segment通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全。

ConcurrentHashMap在初始化的时候会要求初始化concurrencyLevel作为segment数组长度,即并发度,代表最多有多少个线程可以同时操作ConcurrentHashMap,其默认值是16.这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它就不可以扩容了。每个Segment片段里面含有键值对HashEntry数组,是真正存放键值对的地方,这就是ConcurrentHashMap的数据结构。
2.成员变量及构造函数
从上图我们可以看出,ConcurrentHashMap离不开Segment,Segment是ConcurrentHashMap的一个静态内部类,可以看到Segment继承了可重入锁ReentrantLock,想要访问Segment片段,线程必须获得同步锁。部分源码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//尝试获取锁的最多尝试次数,即自旋次数
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
//HashEntry数组,也就是键值对数组
transient volatile HashEntry<K, V>[] table;
//元素的个数
transient int count;
//segment中发生改变元素的操作的次数,如put/remove
transient int modCount;
//当table大小超过阈值时,对table进行扩容,值为capacity *loadFactor
transient int threshold;
//加载因子
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K, V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}
键值对HashEntry是ConcurrentHashMap的基本数据结构,多个HashEntry可以形成链表以解决hash冲突。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
static final class HashEntry<K,V> {
//hash的值
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
/**
* Sets next field with volatile write semantics. (See above
* about use of putOrderedObject.)
*/
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
// Unsafe mechanics
static final sun.misc.Unsafe UNSAFE;
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
ConcurrentHashMap的成员变量及构造方法如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
//默认的初始容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认的并发度,也就是默认的Segment数组长度
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//最大容量,ConcurrentMap最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//每个segment中table数组的长度,必须是2^n,最小为2
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//允许最大segment数量,用于限定concurrencyLevel的边界,必须是2^n
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
//非锁定情况下调用size和contains方法的重试次数,避免由于table连续被修改导致无限重试
static final int RETRIES_BEFORE_LOCK = 2;
//计算segment位置的掩码值
final int segmentMask;
//用于计算算segment位置时,hash参与运算的位数
final int segmentShift;
//Segment数组
final Segment<K,V>[] segments;
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//参数校验
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// 找到一个大于等于传入的concurrentcyLevel的2^n数,且与concurrencyLevel最接近
// ssize作为Segment数组
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 计算每个segment中table的容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
// 确保cap是2^n
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 创建segments并初始化第一个segment数组,其余的segment延迟初始化
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
}
concurrencyLevel参数表示期待并发的修改ConcurrentHashMap的线程数量,用于决定Segment的数量,通过算法可以知道就是找到最接近传入的concurrencyLevel的2的幂次方。而segmentMask和segmentShift看上去有点难以理解,其实其作用就是根据key的hash值做计算定位在哪个Segment片段。我们以调用无参构造为例:
- Segment数组长度为16,不可扩容;
- Segment[i]的默认大小为2,负载因子为0.75,得出初始阈值为1.5,也就是插入第一个元素不会触发扩容,插入第二个进行一次扩容。
- 初始化了Segment[0],其他位置还是null
- 当前segmentShift的值为32-4 = 28, segmentMask为16-1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到。
对于哈希表而言,最重要的就是put()和get()方法了,下面我们来具体分析一下这两个方法。
3. put()方法分析
put(K key, V value)方法其实只有两步:1. 根据键的值定位键值对在哪个Segment片段; 2. 调用Segment的put方法。 下面我们来看一下具体的主流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
//计算键的hash值
int hash = hash(key);
//通过hash值运算把键值对定位到segment[j]片段上
// hash值是32位,无符号右移segementShift(28)位,剩下低4位
//然后和segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的最后 4 位,也就是槽的数组下标
int j = (hash >>> segmentShift) & segmentMask;
//检查segment[j]是否已经初始化了,没有的话调用ensureSegment初始化segment[j]
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
//向片段中插入键值对
return s.put(key, hash, value, false);
}
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
我们从ConcurrentHashMap的构造函数可以发现Segment数组只初始化了Segment[0],其余的Segment是用到了在初始化,用了延迟加载的策略,而延迟加载调用的就是ensureSegment方法。(这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
//按照segment[0]的HashEntry数组长度和加载因子初始化Segment[k]
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 这里我们可以看到为什么之前需要初始化segment[0]了
// 使用当前segment[0] 处的数组长度和负载因子来初始化 segment[k]
// 为什么要用“当前”,因为segment[0]可能早就扩容过了
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
//初始化segment[k]内部的数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck,再一次检查该槽是否被其他线程初始化了
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循环,内部用 CAS,当前线程成功设值或其他线程成功设值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
继续流程,put(K key, int hash, V value, boolean onlyIfAbsent)方法,调用Segment的put方法插入键值对到Segment的HashEntry数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//Segment继承ReentrantLock,尝试获取独占锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
//segment内部的数组
HashEntry<K,V>[] tab = table;
//定位键值对在HashEntry数组上的位置
int index = (tab.length - 1) & hash;
//获取这个位置的第一个键值对
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {//此处有链表结构,一直循环到e==null
K k;
//存在与待插入键值对相同的键,则替换value
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {//onlyIfAbsent默认为false
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//node不为null,设置node的next为first,node为当前链表的头节点
if (node != null)
node.setNext(first);
//node为null,创建头节点,指定next为first,node为当前链表的头节点
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//扩容条件 (1)entry数量大于阈值 (2) 当前数组tab长度小于最大容量。满足以上条件就扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//扩容
rehash(node);
else
//tab的index位置设置为node,头插法
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
我们可以看到,在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut(K key, int hash, V value) 这个方法来获取锁(在不超过最大重试次数MAX_SCAN_RETRIES通过CAS尝试获取锁)。下面我们来具体分析一下这个方法是怎么控制加锁的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
//first,e:键值对的hash值定位到数组tab的第一个键值对
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
//线程循环尝试通过CAS获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
//当e==null或key.equals(e.key)时retry=0,走出这个分支
if (e == null) {
if (node == null) // speculatively create node
//初始化键值对,next指向null
// 进到这里说明数组该位置的链表是空的,没有任何元素
// 当然,进到这里的另一个原因是 tryLock() 失败,所以该槽存在并发,不一定是该位置
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//超过最大自旋次数,阻塞
// 重试次数如果超过 MAX_SCAN_RETRIES(单核1多核64),那么不抢了,进入到阻塞队列等待锁
// lock() 是阻塞方法,直到获取锁后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
//头节点发生变化,重新遍历
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
// 这个时候是有大问题了,那就是有新的元素进到了链表,成为了新的表头
// 所以这边的策略是,相当于重新走一遍这个 scanAndLockForPut 方法
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
上述获取锁的方法看似复杂,其实其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。下面我们看一下扩容的rehash()函数。
强调一下,segment数组不能扩容,扩容是segment数组某个位置内部的数组HashEntry进行扩容,扩容后,容量变为原来的2倍。首先,我们要回顾一下触发扩容的地方,put 的时候,如果判断该值的插入会导致该 segment 的元素个数超过阈值,那么先进行扩容,再插值。该方法不需要考虑并发,因为到这里的时候,是持有该 segment 的独占锁的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
private void rehash(HashEntry<K,V> node) {
//扩容前的旧tab数组
HashEntry<K,V>[] oldTable = table;
//扩容前数组长度
int oldCapacity = oldTable.length;
//扩容后数组长度(扩容前两倍)
int newCapacity = oldCapacity << 1;
//计算新的阈值
threshold = (int)(newCapacity * loadFactor);
//新的tab数组
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
//新的掩码,如从 16 扩容到 32,那么 sizeMask 为 31,对应二进制 ‘000...00011111’
int sizeMask = newCapacity - 1;
//遍历旧的数组
for (int i = 0; i < oldCapacity ; i++) {
//遍历数组的每一个元素
HashEntry<K,V> e = oldTable[i];
if (e != null) {
//元素e指向的下一个节点,如果存在hash冲突那么e不为空
HashEntry<K,V> next = e.next;
//计算元素在新数组的索引
int idx = e.hash & sizeMask;
// 桶中只有一个元素,把当前的e设置给新的table
if (next == null) // Single node on list
newTable[idx] = e;
//桶中有布置一个元素的链表
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
// idx 是当前链表的头结点 e 的新位置
int lastIdx = idx;
// 下面这个 for 循环会找到一个 lastRun 节点,这个节点之后的所有元素是将要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
//k是单链表元素在新数组的位置
int k = last.hash & sizeMask;
//lastRun是最后一个扩容后不在原桶处的Entry
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
//lastRun以及它后面的元素都在一个桶中
newTable[lastIdx] = lastRun;
// Clone remaining nodes
//遍历到lastRun即可
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
//处理引起扩容的那个待添加的节点
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
//把Segment的table指向扩容后的table
table = newTable;
}
这里的扩容比之前的 HashMap 要复杂一些,代码难懂一点。上面有两个挨着的 for 循环,第一个 for 有什么用呢?
仔细一看发现,如果没有第一个 for 循环,也是可以工作的,但是,这个 for 循环下来,如果 lastRun 的后面还有比较多的节点,那么这次就是值得的。因为我们只需要克隆 lastRun 前面的节点,后面的一串节点跟着 lastRun 走就是了,不需要做任何操作。
4. get()方法分析
get获取元素不需要加锁,效率高,获取key定位到的segment片段还是遍历table数组的HashEntry元素时使用了UNSAFE.getObjectVolatile保证了能够无锁且获取到最新的volatile变量的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
//计算key的hash值
int h = hash(key);
//根据hash值计算key在哪个segment片段
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//获取segments[u]的table数组
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//遍历table中的HashEntry元素
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
//找到相同的key,返回value
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
5. size()方法分析
size()方法用来计算ConcurrentHashMap中存储元素的个数。那么在统计所有的Segment元素的个数时是否都需要加上锁呢?如果不上锁在统计的过程可能存在其他的线程并发存储/删除元素,而如果上锁又会降低读写效率。ConcurrentHashMap在实现时使用了折中的办法,它会无锁遍历三次把所有的segment的modCount加到sum里面,如果与前一次遍历结果相比较sum没有改变说明这两次遍历没有其他线程修改ConcurrentHashMap,返回segment的count的和;如果每次遍历与上次相比都不一样那就上锁进行同步。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
//达到RETRIES_BEFORE_LOCK,也就是三次
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
//遍历计算segment的modCount和count的和
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
//是否溢出int范围
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
//last是上一次的sum值,相等跳出循环
if (sum == last)
break;
last = sum;
}
} finally {
//解锁
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
6. remove()方法
调用Segment的remove方法:
1
2
3
4
5
public V remove(Object key) {
int hash = hash(key);
Segment<K,V> s = segmentForHash(hash);
return s == null ? null : s.remove(key, hash, null);
}
remove(Object key, int hash, Object value),获取同步锁,移除指定的键值对
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
final V remove(Object key, int hash, Object value) {
//获取同步锁
if (!tryLock())
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> e = entryAt(tab, index);
//遍历链表用来保存当前链表节点的前一个节点
HashEntry<K,V> pred = null;
while (e != null) {
K k;
HashEntry<K,V> next = e.next;
//找到key对应的键值对
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
V v = e.value;
//键值对的值与传入的value相等
if (value == null || value == v || value.equals(v)) {
//当前元素为头节点,把当前元素的下一个节点设为头节点
if (pred == null)
setEntryAt(tab, index, next);
//不是头节点,把当前链表节点的前一个节点的next指向当前节点的下一个节点
else
pred.setNext(next);
++modCount;
--count;
oldValue = v;
}
break;
}
pred = e;
e = next;
}
} finally {
unlock();
}
return oldValue;
}
我们来看一下其中获取锁的方法scanAndLock(Object key, int hash),其扫描是否含有指定的key并且获取同步锁,当方法执行完毕也就是跳出循环肯定成功获取到同步锁,跳出循环有两种方式:1.tryLock方法尝试获取独占锁成功 2.尝试获取超过最大自旋次数MAX_SCAN_RETRIES线程堵塞,当线程从等待队列中被唤醒获取到锁跳出循环。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private void scanAndLock(Object key, int hash) {
// similar to but simpler than scanAndLockForPut
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
int retries = -1;
while (!tryLock()) {
HashEntry<K,V> f;
if (retries < 0) {
if (e == null || key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
}
7. isEmpty()
检查ConcurrentHashMap是否为空,同样没有使用同步锁,通过两次遍历:
- 确定每个segment是否为0,其中任何一个segment的count不为0,就返回,都为0,就累加modCount为sum;
- 第一个循环执行完还没有退出,map可能为空,再遍历一次,如果这个过程中任何一个segment的count不为0返回false,同时sum减去每个segment的modCount,若循环执行完程序还没有退出,比较sum是否为0,为0表示两次检查没有元素插入,map确实为空,否则map不为空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public boolean isEmpty() {
//累计segment的modCount值
long sum = 0L;
final Segment<K,V>[] segments = this.segments;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
if (seg.count != 0)
return false;
sum += seg.modCount;
}
}
//再次检查
if (sum != 0L) { // recheck unless no modifications
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
if (seg.count != 0)
return false;
sum -= seg.modCount;
}
}
if (sum != 0L)
return false;
}
return true;
}
8. 总结
ConcurrentHashMap引入分段锁的概念提高了并发量,每当线程要修改哈希表时并不是锁住整个表,而是去操作某一个segment片段,只对segment做同步,通过细化锁的粒度提高了效率,相对与HashTable对整个哈希表做同步处理更实用与多线程环境。
参考文章
多线程十一之ConcurrentHashMap1.7源码分析
java集合类(二)(java7 ConcurrentHashMap)
Java7/8 中的HashMap 和 ConcurrentHashMap
1.2.7 ConcurrentHashMap源码分析(JDK 1.8)
前面我们分析了JDK7中是如何实现满足并发且线程安全的ConcurrentHashMap:ConcurrentHashMap根据初始的并发度concurrencyLevel构建片段Segment数组,最多可以实现有concurrencyLevel个线程进行并发读写,相对于HashTable利用synchronized关键字对每个方法做同步大大提高了效率。但是JDK7中ConcurrentHashMap的实现仍然有不足:Segment数组无法扩容,并发度受到Segment数组大小限制,只能支持N个线程的并发(N为Segment数组长度且N不可变)。
Java8中取消了Java7中的分段锁设计。Java7中ConcurrentHashMap有一个“currencyLevel”的概念,指定了哈希表共有多少把锁,在哈希表初始化完成之后不可更改。JDK 1.8中,并发的最小单位不再是JDK7中的Segment片段,而是存储键值对的节点Node(利用CAS操作来保证线程安全),线程操作ConcurrentHashMap时锁住的是装载Node的桶,锁的粒度变得更小了,意味着并发能力进一步增强,另外引入了红黑树来解决多个节点哈希冲突造成查询效率下降的问题。(其实本质上区别不大,都是一种锁条带化(lock-stripping)的思想。)
1. 数据结构
JDK8中不再使用Segment分段锁,而是使用CAS + synchronized来保证并发时的线程安全。

2. 成员变量及构造函数
先来看一下定义的成员变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
//Node桶数组的最大长度:2^30
private static final int MAXIMUM_CAPACITY = 1 << 30;
//Node数组默认长度,必须是2的幂次方
private static final int DEFAULT_CAPACITY = 16;
//转换为数组的最大长度
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//为了兼容性,Java8中没用到这个属性
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//默认的HashMap加载因子
private static final float LOAD_FACTOR = 0.75f;
//链表转红黑树阈值,同一个桶中因为hash冲突的链表节点超过8个就转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
//红黑树转链表阈值
static final int UNTREEIFY_THRESHOLD = 6;
//树化最小Node数组长度
static final int MIN_TREEIFY_CAPACITY = 64;
//扩容时单个线程推进最小步长,在扩容那里详细解释用途
private static final int MIN_TRANSFER_STRIDE = 16;
// 用于对Node数组tab生成一个stamp
private static int RESIZE_STAMP_BITS = 16;
//2^15-1,用于帮助扩容的最大线程数量
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
//sizeCtl中记录size大小的偏移量
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
//特定Node的hash值,程序中根据这些hash值判定Node类型
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//运行环境CPU数量,transfer扩容时会用到这个参数
static final int NCPU = Runtime.getRuntime().availableProcessors();
}
其中,一个重要的成员变量sizeCtl:控制标识符,用来控制table初始化和扩容操作的,当ConcurrentHashMap处于不同的状态阶段时,sizeCtl的值也不同,代表的含义也不同:
- sizeCtl = -1,表示有线程正在进行真正的初始化操作;
- sizeCtl = -(1 + nThreads),表示有nThreads个线程正在进行扩容操作;
- sizeCtl > 0, 分为两种情况:如果table数组还未初始化,这就是初始化数组的长度;如果已经初始化了,sizeCtl是table数组长度的0.75倍,代表扩容阈值;
- sizeCtl = 0, 默认值,此时在真正的初始化操作中使用默认容量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//存放键值对Node数组
transient volatile Node<K,V>[] table;
//扩容时指向新生成的数组,不扩容为null
private transient volatile Node<K,V>[] nextTable;
//用于统计哈希表中键值对个数
private transient volatile long baseCount;
//控制标识符,当ConcurrentHashMap处于初始化/扩容等不同状态,sizeCtl的值也不同,表示的意义也不同
private transient volatile int sizeCtl;
//扩容时线程把数据从老数组向转移的起点
private transient volatile int transferIndex;
给出构造方法如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
//初始化根据这个歌值作为桶数组table的长度
this.sizeCtl = cap;
}
从上面可以看到调用构造方法创建ConcurrentHashMap对象时,只是根据传入参数计算桶数组初始长度赋值给sizeCtl,并没有初始化table数组,延迟加载。
3. 内部类
首先介绍一下Node类吧,其用于存储key-value键值对,当哈希冲突映射到同一个桶中会形成链表,Node是ConcurrentHashMap中最基础的数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
//get方法会调用find方法,子类也会重写find方法
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
ForwardingNode子类: 继承父类Node,不存储键值对,是一个标记节点,ForwardingNode的hash值固定为MOVED(-1).当ConcurrentHashMap处于扩容阶段时会把数据从老的table数组赋值到新的扩容后的table数组,每当完成一个桶,就会在老数组的桶的位置上放上ForwardingNode表示这个位置已经复制完成,如果要这个地方的Node键值对,就去扩容后的nextTable中去寻找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
//寻找key为k且hash值为h的键值对节点
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
TreeBin子类:当链表转换为红黑树时,table数组存储的并不是红黑树的根节点,而是TreeBin节点,用来标识这里存放的是一个红黑树,不存储键值对数据,而是指向红黑树的根节点root.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
/**
* Creates bin with initial set of nodes headed by b.
*/
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode<K,V> r = null;
for (TreeNode<K,V> x = b, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x);
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
...
}
TreeNode子类:用于构建红黑树的基础数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}
4. put()方法解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//校验参数合法性
if (key == null || value == null) throw new NullPointerException();
// 计算键的hash值
int hash = spread(key.hashCode());
// 用来保存桶中的节点个数,判断是否需要转换为红黑树
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table桶数组还没有初始化,那么调用initTable初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// key的hash值映射到的桶为空,也就是没有存放过键值对,直接把键值对存放到这个桶里
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//桶内的节点是ForwardingNode,ConcurrentHashMap处于扩容阶段,让当前线程帮助扩容
else if ((fh = f.hash) == MOVED)
//helpTransfer在扩容里详细分析
tab = helpTransfer(tab, f);
// 如果不是以上情况,说明桶中已经有元素,可能是一个链表,可能是红黑树
else {
V oldVal = null;
//把桶中元素锁住
synchronized (f) {
if (tabAt(tab, i) == f) {
// fh是桶中节点的hash值,大于零说明不是TreeBin,是链表
if (fh >= 0) {
binCount = 1;
//循环遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 链表中有键值对的键与要插入的键相同,直接替换value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 把键值对插入链表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// fh小于0,桶中存放的是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//桶中键值对总数,检查是否需要把链表转为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//更新ConcurrentHashMap中存放键值对个数
addCount(1L, binCount);
return null;
}
我们来简要分析一下过程:
- 获取key的hash值,找到数组下标;
- 如果数组为空,进行数组初始化;
- 判断该数组第一个节点是否有数据,如果没有数据,则使用CAS操作将这个新值插入,如果有数据,则进入第四步;
- 对头节点进行加锁(synchronized),如果头节点的hash值 >= 0,说明是链表,遍历链表,如果找到相等的key,则进行覆盖,如果没有找到相等的key,则将新值放到链表的最后面;如果hash值 < 0,说明是红黑树,调用红黑树的插值方法插入新节点。
- 插值完成之后,判断链表元素是否达到临界值(8),那么就会进行红黑树转换。注意:当数组长度小于64的时候,即使达到临界值也不会进行红黑树转换,而是进行数组扩容。
我们先来看一下ConcurrentHashMap是如何定位数组下标的:
1
2
3
4
5
6
7
8
9
10
11
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//hash扰动
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
// 获取table对应的索引元素f
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
可以看到采用Unsafe.getObjectVolatie()来获取,而不是直接用table[index]的原因跟ConcurrentHashMap的弱一致性有关。在java内存模型中,我们已经知道每个线程都有一个工作内存,里面存储着table的副本,虽然table是volatile修饰的,但不能保证线程每次都拿到table中的最新元素,Unsafe.getObjectVolatile可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
4.1 initTable()
通过构造器的源码我们知道构造器新建ConcurrentHashMap对象只是设定了table数组的长度,没有初始化,通过initTable来实现延迟加载的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// sizeCtl < 0表示有其他线程在初始化,挂起当前线程
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// sizeCtl设为-1,由当前线程复杂桶数组的初始化
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//根据参数设置数组长度
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// sizeCtl为0.75n,达到0.75n的阈值就开始扩容
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
4.2 table扩容
什么时候会触发扩容操作?
- put时如果发现哈希表当前节点的hash == MOVED,代表当前哈希表正在扩容,当前线程尝试去帮助扩容;
- 如果新增节点后,所在的链表的元素个数大于等于8,则会调用treeifyBin把链表转换为红黑树。在转换结构时,若tab的长度小于
MIN_TREEIFY_CAPACITY,默认值为64,则会将数组长度扩大到原来的两倍,并触发transfer,重新调整节点位置。(只有当tab.length >= 64,ConcurrentHashMap才会使用红黑树) - 新增节点后,
addCount统计tab中的节点个数大于阈值(sizeCtl),会触发transfer,重新调整节点位置。
我们先来看一下addCount()方法(源码中的helpTransfer()方法等会再讲),其扩容部分可分为以下几个步骤:
- 检查当前ConcurrentHashMap中存储的键值对个数是否超过阈值sizeCtl:
s >= (long)(sc = sizeCtl) - 检查是否还有别的线程已经开始给ConcurrentHashMap扩容,如果已经开始:
- 检查是否完毕,扩容完毕,跳出检查
- 还在扩容中,当前线程加入扩容,sizeCtl加一
- 没有别的线程开始扩容,当前线程是开启扩容的第一个线程,CAS设置sizeCtl小于0,表示扩容已经开始。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// CAS更新baseCount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
// CAS更新CountCell
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
//检查是否需要扩容
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//键值对的的个数超过了阈值sizeCtl
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// 根据当前桶数组长度生成扩容戳
int rs = resizeStamp(n);
// sc < 0表示扩容已经开始
if (sc < 0) {
// 扩容完毕
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//当前线程假如扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//当前线程是开始扩容的第一个线程
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
从上面的分析中可以看到在扩容的流程中sizeCtl是一个很重要的状态量,sizeCtl可以表示扩容是否开始,以及参与扩容线程的个数。如果线程是第一个开始扩容的线程的话,会把sizeCtl以CAS的方式设置为(rs << RESIZE_STAMP_SHIFT) + 2,这个rs是由resizeStamp方法生成的:
1
2
3
4
5
static final int resizeStamp(int n) {
// numberOfLeadingZeros:该方法的作用是返回无符号整型i的最高非零位前面的0的个数,包括符号位在内
// 1 << (RESIZE_STAMP_BITS - 1):把1左移(RESIZE_STAMP_BITS - 1)位,也就是15位
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
resizeStamp是根据传入的桶数组长度生成一个扩容戳(resizeStamp),我们知道桶数组长度,也就是我们传入的n的2的幂次方,Integer.numberOfLeadingZeros(n)返回n的最高位非零位前面的0的个数,再与1左移15位的结果异或得到生成的戳,如果我们传入的默认桶数组长度16,返回的结果是32795,计算结果如下:

可以看到当桶数组长度为16的ConcurrentHashMap开始扩容时,resizeStamp的返回值是0000 0000 0000 0000 1000 0000 0001 1011,也就是32795。当第一个线程开始扩容时,会设置sizeCtl的值为(rs << RESIZE_STAMP_SHIFT) + 2,如下:

此时sizeCtl的值二进制形式为1000 0000 0001 1011 0000 0000 0000 0010,sizeCtl分为两部分,它的高16位由rs << RESIZE_STAMP_SHIFT的结果组成,如果有n个线程加入扩容,低16位的值为1+n。由于此时sizeCtl的符号位为1,所以处于扩容状态sizeCtl的值总是小于0的负数。
transfer(Node<K,V>[] tab, Node<K,V>[] nextTab)
transfer是扩容的核心方法,也可以说是ConcurrentHashMap中设计最巧妙的方法了。传入两个参数,tab指向扩容前的数组,nextTab指向数据要转移过去的新数组,第一个开始扩容的线程调用transfer方法传入的nextTab参数为空,后续扩容线程传入的是成员变量nextTab。
transfer方法开始把键值对从扩容前的数组转移到新数组,这个方法并不是同步的,不是说开始扩容的线程负责转移所有的数据,并发大师Doug Lea让每个参与扩容的线程负责转移老数组的一部分数据,转移完了以后如果扩容还没有结束再取一段数据,转移数据的过程是并发的,最多可以有MAX_RESIZERS(2^16)个线程同时参与,大致过程如下所示:

从上图可以看出,线程转移数据是从后往前开始的,当转移过程发现index < 0说明扩容结束。具体ConcurrentHashMap是怎么迁移数据的,下面以桶中的链表为例说明。如下图所示8号桶中有6个链表节点,扩容线程会把这些节点分为两部分:节点hash值与数组长度做与运算结果为0的节点放到低位桶,结果为1的放到高位桶,然后把低位桶放到新数组索引为8的桶中,把高位桶放到索引为24(i + n)的桶中。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//确定每个线程一次扩容负责处理多少个桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 扩容的新桶数组nextTable若为空,构建数组
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// 新数组长度是现在数组长度两倍,N = 2n
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
//更新成员变量
nextTable = nextTab;
// 初始化transferIndex,从旧数组的末尾开始
transferIndex = n;
}
int nextn = nextTab.length;
// 当线程完成一个桶的数据转移,就在旧数组桶的位置上放上ForwardingNode标记节点,指向转移后的新节点
// 用来标记这个桶数据已经迁移完成
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 首次推进为true,如果等于true,说明需要再次推进一个下标(i--),反之,如果是false,那么久不能推进下标,需要将当前的下标处理完毕后才能继续推进
boolean advance = true;
// 扩容是否完成标记位
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// advance为true,线程向前推进,使得i--,i就是要处理的桶的索引,bound表示区间的下界
// transferIndex是区间的上界, i < bound说明线程处理完这个区间的数据
while (advance) {
int nextIndex, nextBound;
// 更新迁移索引i
if (--i >= bound || finishing)
advance = false;
// transferIndex <= 0 扩容完毕
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// CAS 修改transferIndex, 即 length - 区间值,留下剩余的区间值供后面的线程使用
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 检查扩容是否完成或当前线程是否完成任务
// i < 0扩容完成
// i >=tab.length 或 i + tab.length >= nextTable.length 都不可能发生
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// finishing为true,说明已经扩容完成
if (finishing) {
// 把nextTable设置为null
nextTable = null;
// table指向扩容后的桶数组
table = nextTab;
// 设置下次扩容阈值sizeCtl,这里的n是扩容前旧数组的长度
// sizeCtl = 2n -0.5n = 1.5n 新数组长度N= 2n,加载因子: 1.5/2n = 0.75n
// 从这里可以看出即使构造方法传入的加载因子不是0.75也不影响
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// finishing 不为true,尝试将sc - 1,表示这个线程结束帮助扩容;将sc的低16位减1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 如果sc - 2不等于标识符左移16位,如果他们相等了,说明没有线程在帮助他们扩容了。
// 也就是说,扩容结束了。不相等说明没有结束,但是当前线程的扩容任务完成了
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//相等,说明扩容已经完成了
finishing = advance = true;
i = n; // recheck before commit
}
}
//正式开始迁移数据到新的桶数组
//如果i对应的桶为null,直接把标志节点放到桶中
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 根据hash值判断i对应的桶中节点为ForwardingNode,说明这个桶已经被处理过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
//桶中有可能是链表节点Node,也可能是红黑树节点TreeBin
else {
//把桶中节点锁住,防止插入或删除
synchronized (f) {
if (tabAt(tab, i) == f) {
// ln:低位桶 hn:高位桶
Node<K,V> ln, hn;
// 桶中节点hash值大于0,是链表类型节点Node
if (fh >= 0) {
// runBit由节点hash值与旧数组的长度做与运算,由于数组长度是2的幂次方,所以runBit要么为1,要么为0
int runBit = fh & n;
// 从链表尾部到lastRun节点,runBit值相同
Node<K,V> lastRun = f;
// 循环遍历找lastRun节点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
// runBit为0,从lastRun到链表尾结点都放到ln低位桶
if (runBit == 0) {
ln = lastRun;
hn = null;
}
//否则放到高位桶
else {
hn = lastRun;
ln = null;
}
//从链表头部遍历到lastRun节点,节点的runBit为0放到地位桶,为1放到高位桶
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
// 头插法
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//插入到新桶数组中
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// 在旧数组的桶中放入标记节点
setTabAt(tab, i, fwd);
advance = true;
}
// 桶中节点为红黑树,处理逻辑和上面相似
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
helpTransfer(Node<K,V>[] tab, Node<K,V> f)
除了addCount会在检查是否需要扩容的时候触发transfer方法,当putVal方法添加的键值对映射到对应的桶中节点类型为ForwardingNode时,也出触发扩容,也就是下面这段代码:
1
2
3
4
5
6
7
...
else if ((fh = f.hash) == MOVED)
//helpTransfer在扩容里详细分析
tab = helpTransfer(tab, f);
// 如果不是以上情况,说明桶中已经有元素,可能是一个链表,可能是红黑树
else {
...
会调用helpTransfer方法帮助扩容,下面重点分析程序中的这一段扩容是否完成的if条件:
(sc >>> RESIZE_STAMP_SHIFT)!=rs- 在我们分析
sizeCtl时知道:当第一个开始给ConcurrentHashMap扩容时,会设置sizeCtl的值为(rs << RESIZE_STAMP_SHIFT) + 2,从transfer方法可以知道,当扩容结束时会设置sizeCtl = (n << 1) - (n >>> 1)重新变为正数。所以当(sc >>> RESIZE_STAMP_SHIFT) != rs的时候说明此时sizeCtl的值为(n << 1) - (n >>> 1),扩容已经结束了。
- 在我们分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
//检查扩容是否结束
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
// 扩容完毕
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
// 当前线程加入扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
4.3 链表转为红黑树
上面介绍完扩容过程,我们再次回到put流程,在第四步中是向链表或者红黑树里加节点,到第五步,会调用treeifyBin()方法进行链表转红黑树的过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//如果整个table的数量小于64,就扩容至原来的一倍,不转红黑树了
//因为这个阈值扩容可以减少hash冲突,不必要去转红黑树
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
//封装成TreeNode
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
//通过TreeBin对象对TreeNode转换成红黑树
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
5. get()方法
get()方法比较简单,根据key获取保存的键值对的value,主要有以下几步:
- 计算key的hash值;
- 根据hash值映射到桶数组对应的桶,映射:(n-1) & h
- 根据桶中元素是否是链表寻找对应的key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 计算key的hash值
int h = spread(key.hashCode());
// 判断桶数组不为空并且找到了key对应的桶
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//桶中第一个元素就是要找的键
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 桶中元素是ForWarding或者TreeBin
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//继续在桶的单链表中寻找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
6. size()方法
size方法用来统计ConcurrentHashMap中存储的键值对个数,可以看到其中调用了sumCount()方法,而sumCount方法就是统计baseCount和CountCell数组的和。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public int size() {
//调用sumCount()方法
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
可以看到sumCount()就是统计baseCount和CountCell数组的和,为什么要这样统计呢?在putVal方法的末尾会调用addCount方法更新键值对的个数,去看看addCount方法的第一部分(更新键值对数量部分)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
//CAS更新baseCount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//CAS更新CountCell
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
//检查是否需要扩容
......
}
addCount()方法分为两个部分,一部分是更新键值对数量,另一部分是检查是否需要扩容。更新键值对数量先通过CAS更新baseCount,如果CAS更新失败,说明线程并发竞争激烈,就通过CAS加死循环把要更新的值加到CounterCell数组中,所以键值对的总数是baseCount以及遍历CounterCell的和。
mappingCount(): 我们在回头看一下size方法:因为n是long类型的,而size方法的返回值是int类型,所以会比较n是否超出了int范围
1
2
3
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
如果超出了范围就返回Integer.MAX_VALUE。为什么键值对的数量会超出int范围呢?虽然ConcurrentHashMap中定义了常量MAXIMUM_CAPACITY限定了table数组的最大长度(2^30),但是由于hash冲突的原因一个桶中可能存储多个键值对,数据量大的情境下是有可能超过int范围,所以JDK建议使用mappingCount方法,实现与size方法一致返回值为long类型,不受int范围限制。
1
2
3
4
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
7. clear()
清空tab的过程如下所示,遍历tab中的每一个bucket:
- 当前bucket正在扩容,先协助扩容;
- 给当前bucket上锁,删除元素;
- 更新map的size
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public void clear() { // 移除所有元素
long delta = 0L; // negative number of deletions
inti = 0;
Node<K,V>[] tab = table;
while (tab != null && i < tab.length) {
intfh;
Node<K,V> f = tabAt(tab, i);
if (f == null) // 为空,直接跳过
++i;
else if ((fh = f.hash) == MOVED) { //检测到其他线程正对其扩容
//则协助其扩容,然后重置计数器,重新挨个删除元素,避免删除了元素,其他线程又新增元素。
tab = helpTransfer(tab, f);
i = 0; // restart
}
else{
synchronized (f) { // 上锁
if (tabAt(tab, i) == f) { // 其他线程没有在此期间操作f
Node<K,V> p = (fh >= 0 ? f :
(finstanceof TreeBin) ?
((TreeBin<K,V>)f).first : null);
while (p != null) { // 首先删除链、树的末尾元素,避免产生大量垃圾
--delta;
p = p.next;
}
setTabAt(tab, i++, null); // 利用CAS无锁置null
}
}
}
}
if (delta != 0L)
addCount(delta, -1); // 无实际意义,参数check<=1,直接return。
}
8.总结
- Java8 ConcurrentHashMap取消了分段锁的设计,加锁粒度是哈希表Node[] table数组的每个元素。本质上都是一种锁粗化的思想。
- 采用多线程方式扩容哈希表,每个线程负责一部分节点的迁移工作,加速了扩容过程。
- 在Java7 ConcurrentHashMap数组+链表的基础上加入了红黑树,进一步提高查找效率。
ConcurrentHashMap 在1.7与1.8中的不同
| 项目 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 同步机制 | 分段锁,每个segment继承ReentrantLock | CAS + synchronized保证并发更新 |
| 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 键值对 | HashEntry | Node |
| put操作 | 多个线程同时竞争获取同一个segment锁,获取成功的线程更新map;失败的线程尝试多次获取锁仍未成功,则挂起线程,等待释放锁 | 访问相应的bucket时,使用synchronized关键字,防止多个线程同时操作同一个bucket,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;更新了节点数量还需要考虑扩容和链表转红黑树。 |
| size实现 | 统计每个Segment对象中的元素个数,然后进行累加,但是这种方式计算出来的结果并不一样的准确的。为此,先采用不加锁的方式,连续计算元素的个数,最多计算3次;如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;如果前后两次计算结果都不相同,则给每个Segment进行加锁,再计算一次元素的个数。 | 通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数。 |
ConcurrentHashMap能完全替代HashTable吗?
HashTable虽然性能上不如ConcurrentHashMap,但是并不能完全被取代,两者的迭代器的一致性不同。HashTable的迭代器是强一致性的,而ConcurrentHashMap是弱一致性的。ConcurrentHashMap的get,clear,iterator都是弱一致性的。
- Hashtable的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,效率较低。
- oncurrentHashMap 是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处 是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分数据。
参考文章:
ConcurrentHashMap能完全替代HashTable吗?
https://www.cnblogs.com/rain4j/p/11021736.html
Java7/8 中的HashMap 和 ConcurrentHashMap
ConcurrentHashMap在jdk1.8和1.7中的区别
【JAVA秒会技术之ConcurrentHashMap】JDK1.7与JDK1.8源码区别
ConcurrentHashMap源码分析_JDK1.8版本