“Only those who have the patience to do simple things perfectly ever acquire the skill to do difficult things easily.”
1.二叉树定义
每个节点至多拥有两棵子树(即二叉树中不存在度大于2的结点),并且,二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树有以下性质:
- 若二叉树的层次从0开始,则在二叉树的第i层至多有2^i个节点(i>=0)
- 高度为k的二叉树最多有2^(k+1)-1个节点(k>=-1)。(空树的高度为-1)
- 对任何一棵二叉树,如果其叶子节点(度为0)数为m,度为2的节点数为n,则m = n + 1.
1.1 完美二叉树(Perfect Binary Tree)
一个深度为k(>=-1)且有2^(k+1) - 1个结点的二叉树称为完美二叉树。 (又被称为”满二叉树”)
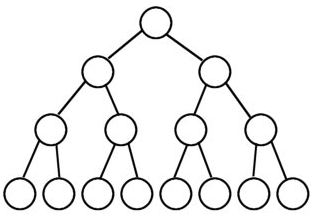
1.2 完全二叉树(Complete Binary Tree)
完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。
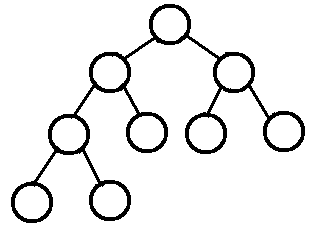
1.3 完满二叉树(Full Binary Tree)
所有非叶子结点的度都是2。(只要你有孩子,你就必然是有两个孩子。)
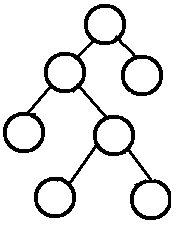
1.4 总结
- 完美(Perfect)二叉树一定是完全(Complete)二叉树,但完全(Complete)二叉树不一定是完美(Perfect)二叉树。
- 完美(Perfect)二叉树一定是完满(Full)二叉树,但完满(Full)二叉树不一定是完美(Perfect)二叉树。
- 完全(Complete)二叉树可能是完满(Full)二叉树,完满(Full)二叉树也可能是完全(Complete)二叉树。
- 既是完全(Complete)二叉树又是完满(Full)二叉树也不一定就是完美(Perfect)二叉树。
2.哈夫曼树定义
首先给出哈夫曼树的一些定义:
- 节点之间的路径长度:在树中从一个节点到达另一个节点所经历的分支,构成了这两个节点间的路径上的经过的分支数称为它的路径长度。
- 树的路径长度:从树的根节点到树中每一节点的路径长度之和。在节点数目相同的二叉树中,完全二叉树的路径长度最短。
- 节点的权:在一些应用中,赋予树中节点的一个有某种意义的实数。
- 节点的带权路径长度:节点到树根之间的路径长度与该节点上权的乘积。
- 树的带权路径长度(Weighted Path Length of Tree:WPL):定义为树中所有叶子节点的带权路径长度之和。
例如如下图所示的二叉树中,给出了带权路径长度的计算方式:
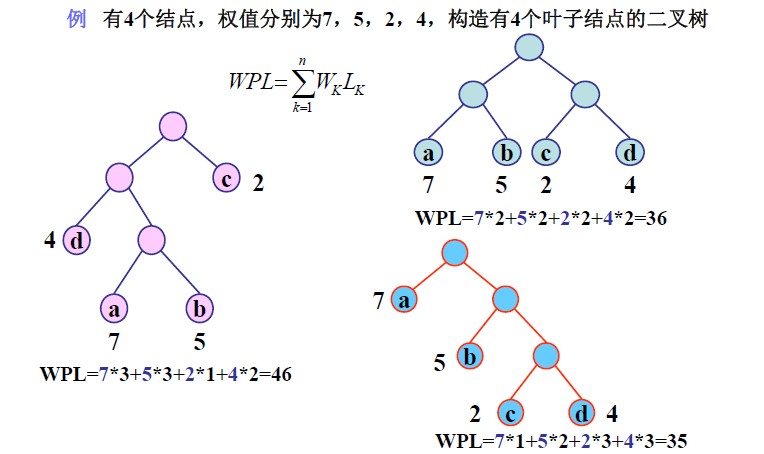
一般来说,用n(n>0)个带权值的叶子来构造二叉树,限定二叉树中除了这n个叶子节点外只能出现度为2的节点。那么符合这样条件的二叉树往往可以构造出许多棵。其中带权路径长度最小的二叉树就称为哈夫曼树或者最优二叉树。(最优二叉树的特点是带权值的节点都是叶子节点,权重越小的节点,其到根节点的路径越长)
注意:
- 叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
- 最优二叉树中,权越大的叶子离根越近。
- 最优二叉树的形态不唯一,WPL最小。
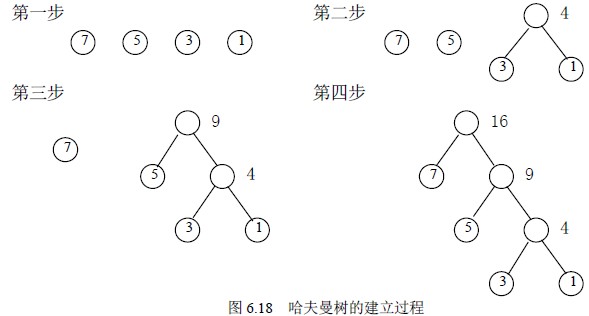
3.哈夫曼树的构造
根据哈夫曼树的定义,一棵二叉树要使得WPL最小,必须使得权重越大的叶子节点越靠近根节点,而权值越小的叶子节点越远离根节点。其基本构造思想如下所示:
- 根据给定的n个权重{w1, w2, w3, w4…wn}构成n棵二叉树的森林F ={T1, T2, T3…..Tn},其中每棵二叉树只有一个权重为wi的根节点,其左右子树都为空;
- 在森林F中选择两课根节点的权重最小的二叉树,作为一棵新的二叉树的左右子树,且令新的二叉树的根节点的权重为其左右子树的权值和;
- 从F中删除被选的两颗子树,并且把构成的新的二叉树加到F森林中;
- 重复2,3操作,直到森林只含有一棵二叉树为止,此时得到的这课二叉树就是哈夫曼树。
构造过程如下图所示:
4.哈夫曼树的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
public class MyHuffmanTree {
public static class Node<E>{
E data;
double weight;
Node leftChild;
Node rightChild;
public Node(E data, double weight){
super();
this.data = data;
this.weight = weight;
}
@Override
public String toString(){
return "Node[data=" + data + ", weight=" + weight + "]";
}
}
/**
* 构造哈夫曼树
* @param nodes 节点集合
* @return DataStructure.Tree.MyHuffmanTree.Node 构造出来的哈夫曼树的根节点
* @author wangming
* @date 2019/8/29 11:11
*/
public static Node createTree(List<Node> nodes){
//只有nodes集合还有两个以上的节点
while (nodes.size() > 1){
quickSort(nodes);
//获取权重最小的两个节点
Node left = nodes.get(0);
Node right = nodes.get(1);
//生成新节点,节点的权值为两个子节点的权值之和
Node parent = new Node(null,left.weight + right.weight);
//让新节点作为两个权重最小节点的父节点
parent.leftChild = left;
parent.rightChild = right;
//删除权重最小的两个节点
nodes.remove(0);
nodes.remove(0);
//新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
}
public static void quickSort(List<Node> nodes){
subSort(nodes,0,nodes.size()-1);
}
/**
* 实现快排算法,用于对节点进行排序
* @param nodes
* @param start
* @param end
* @return void
* @author wangming
* @date 2019/8/29 11:26
*/
public static void subSort(List<Node> nodes, int start, int end){
if(end <= start){
return;
}
int partition = partition(nodes,start,end);
subSort(nodes,start,partition-1);
subSort(nodes,partition+1,end);
}
private static int partition(List<Node> nodes, int left, int right){
Node base = nodes.get(left);
int i = left;
int j = right;
while (i < j){
while (i < j && nodes.get(j).weight >= base.weight){
j--;
}
while (i < j && nodes.get(i).weight <= base.weight){
i++;
}
swap(nodes,i,j);
}
swap(nodes,left,j);
return j;
}
private static void swap(List<Node> nodes, int i, int j){
Node temp = nodes.get(i);
nodes.set(i,nodes.get(j));
nodes.set(j,temp);
}
/**
* 树的层次遍历(广度优先遍历)
* @param root
* @return java.util.List<DataStructure.Tree.MyHuffmanTree.Node>
* @author wangming
* @date 2019/8/29 17:25
*/
public static List<Node> breadthFirst(Node root){
Queue<Node> queue = new ArrayDeque<>();
List<Node> list = new ArrayList<>();
if(root != null){
//将根元素加入队列
queue.offer(root);
}
while (!queue.isEmpty()){
list.add(queue.peek());
Node p = queue.poll();
if(p.leftChild != null){
queue.offer(p.leftChild);
}
if(p.rightChild != null){
queue.offer(p.rightChild);
}
}
return list;
}
public static void main(String[] args) {
List<Node> nodes = new ArrayList<>();
nodes.add(new Node("A",40.0));
nodes.add(new Node("B", 8.0));
nodes.add(new Node("C", 10.0));
nodes.add(new Node("D", 30.0));
nodes.add(new Node("E", 10.0));
nodes.add(new Node("F", 2.0));
Node root = MyHuffmanTree.createTree(nodes);
List<Node> result = breadthFirst(root);
result.forEach((e) ->{
System.out.println(e.data);
});
}
}
构造哈夫曼树的关键流程如下:
- 对list集合中所有节点进行排序;
- 找出list集合中权重最小的两个节点;
- 以权值最小的两个节点作为子节点创建新节点;
- 从list集合中删除权值最小的两个节点,将新节点添加到list集合中。
- 程序采用循环不断执行上面的步骤,直到list集合中只剩下一个节点,最后剩下的这个节点就是哈夫曼树的头节点。
5.哈夫曼编码
在电文传输中,需要将电文中出现的每个字符进行二进制编码。在设计编码时需要遵守两个原则:
- 发送方传输的二进制编码,到接收方解码后必须具有唯一性,即解码结果与发送方发送的电文完全一样。
- 发送的二进制编码尽可能短。
下面我们来看看两种常用的编码方式:
1.等长编码
这种编码方式的特点是每个字符的编码长度相同(编码长度就是每个编码所含的二进制位数)。假设字符集只含有4个字符A,B,C,D,用二进制两位表示的编码分别为00,01,10,11。若现在有一段电文为:ABACCDA,则应发送二进制序列:00010010101100,总长度为14位。当接收方接收到这段电文后,将按两位一段进行译码。这种编码的特点是译码简单且具有唯一性,但编码长度并不是最短的。
2.不等长编码
在传送电文时,为了使其二进制位数尽可能地少,可以将每个字符的编码设计为不等长的,使用频度较高的字符分配一个相对比较短的编码,使用频度较低的字符分配一个比较长的编码。例如,可以为A,B,C,D四个字符分别分配0,00,1,01,并可将上述电文用二进制序列:000011010发送,其长度只有9个二进制位,但随之带来了一个问题,接收方接到这段电文后无法进行译码,因为无法断定前面4个0是4个A,1个B、2个A,还是2个B,即译码不唯一,因此这种编码方法不可使用。
因此,为了设计长短不等的编码,以便减少电文的总长,还必须考虑编码的唯一性,即在建立不等长编码时必须使用任何一个字符的编码都不是另外一个字符的前缀,这宗编码称为前缀编码。哈夫曼树为此就可以用来解决报文编码的问题。
- 利用字符集中每个字符的使用频率作为权值构造一个哈夫曼树;
- 从根节点开始,为到每一个叶子节点路径上的左分支赋予0,右分支赋予1,并从根到叶子节点方向形成叶子节点的编码。
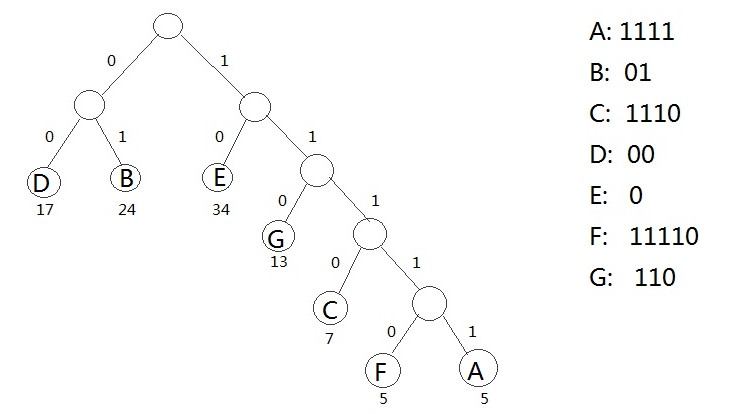
给出下面一个例题:
假设一个文本文件TFile中只包含7个字符{A,B,C,D,E,F,G},这7个字符在文本中出现的次数为{5,24,7,17,34,5,13},利用哈夫曼树可以为文件TFile构造出符合前缀编码要求的不等长编码.
具体做法:
- 将TFile中7个字符都作为叶子结点,每个字符出现次数作为该叶子结点的权值;
- 规定哈夫曼树中所有左分支表示字符0,所有右分支表示字符1,将依次从根结点到每个叶子结点所经过的分支的二进制位的序列作为该结点对应的字符编码
- 由于从根结点到任何一个叶子结点都不可能经过其他叶子,这种编码一定是前缀编码,哈夫曼树的带权路径长度正好是文件TFile编码的总长度。
为此,通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code),给出上面的例子如下所示: